В умовах сучасної цифрової економіки, де кожна хвилина простою сайту або корпоративного додатка конвертується в тисячі доларів збитків та втрату репутації, моніторинг серверів перестає бути просто “технічним завданням”. Сьогодні це стратегічна необхідність. Якщо ваша інфраструктура недоступна, для клієнта вашого бізнесу просто не існує.
Для CTO, IT-директорів та власників компаній в Україні, що зростають, питання стабільності стоїть особливо гостро. Враховуючи міграцію в хмари (Azure, AWS, GCP) та гібридні моделі роботи, 24/7 підтримка серверів стає фундаментом, на якому будується довіра користувачів.
У цій статті ми глибоко розберемо, як працює сучасний моніторинг, які метрики є критичними для бізнесу та як побудувати систему, яка попереджає проблему до того, як її помітить клієнт.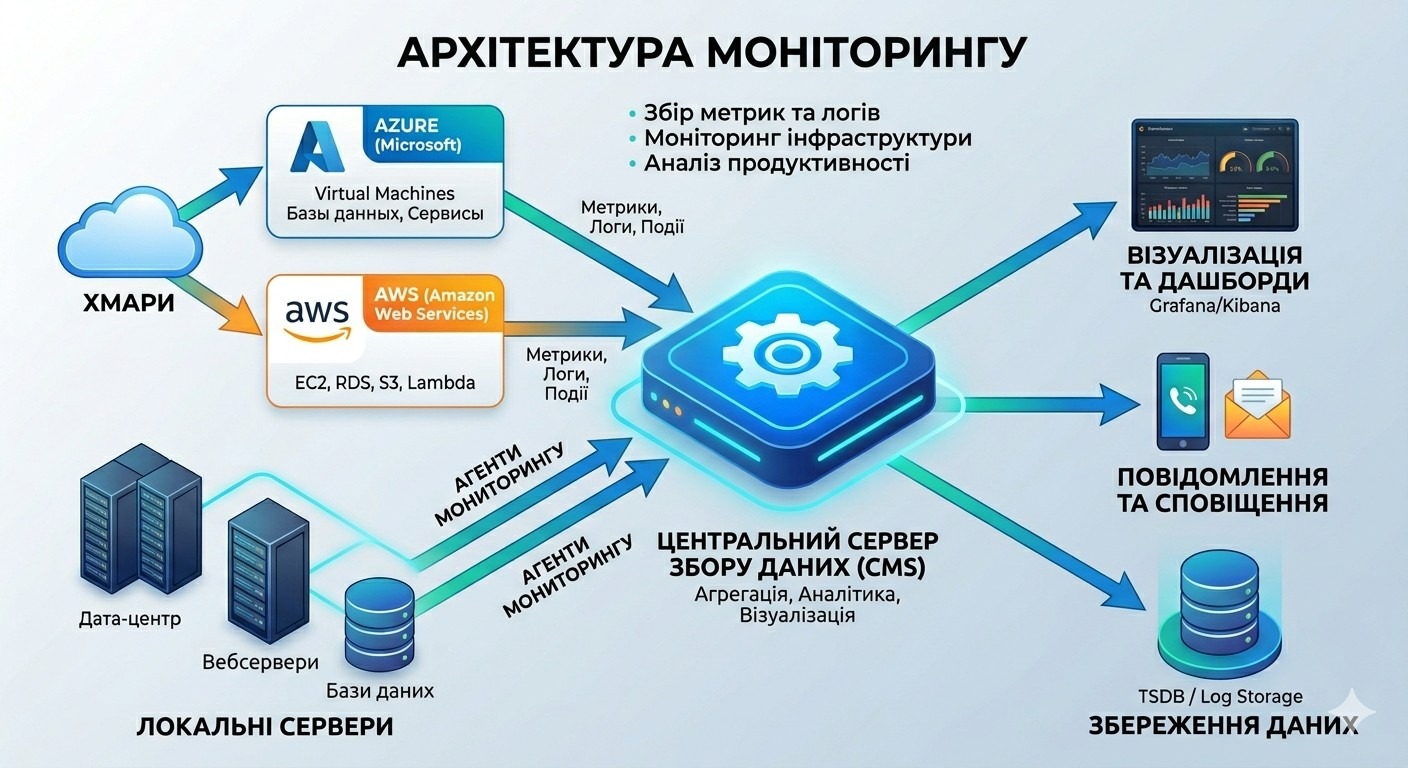
Що таке моніторинг серверів і чому «перевірки раз на годину» більше не працюють
Моніторинг серверів — це процес безперервного збору, аналізу та візуалізації даних про стан апаратного та програмного забезпечення. Це “пульс” вашої IT-системи.
Раніше системним адміністраторам було достатньо періодично перевіряти доступність сервера за допомогою PING. У 2026 році цього катастрофічно замало. Сучасний додаток — це складна екосистема мікросервісів, баз даних та зовнішніх API. Якщо сервер “пінгується”, це не означає, що користувачі можуть здійснити покупку.
Чому 24/7 — це стандарт, а не розкіш?
- Глобалізація: Ваші клієнти можуть перебувати в різних часових поясах.
- Складність інфраструктури: Контейнеризація (Kubernetes/AKS) вимагає миттєвої реакції на падіння подів.
- Безпека: Підозрілі сплески трафіку вночі можуть бути ознакою початку DDoS-атаки або спроби зламу.
Навіщо бізнесу потрібен цілодобовий моніторинг: 5 ключових причин
1. Мінімізація збитків від простоїв (Downtime)
Згідно з дослідженнями Gartner, середня вартість години простою ІТ-систем для великого бізнесу становить близько $300,000. Для середнього бізнесу в Україні цифри скромніші, але не менш болючі. Цілодобовий моніторинг дозволяє скоротити час реакції (MTTR — Mean Time To Recovery) з годин до хвилин.
2. Дотримання SLA (Service Level Agreement)
Якщо ви надаєте послуги іншим компаніям, у вашому контракті напевно прописаний аптайм (наприклад, 99.9%). Без системи контролю 24/7 ви не зможете гарантувати виконання цих зобов’язань і ризикуєте отримати штрафні санкції.
3. Оптимізація ресурсів та планування бюджету
Моніторинг показує не лише помилки, а й навантаження. Ви бачите, коли процесор завантажений на 90%, а коли пам’ять простоює. Це дозволяє вчасно проводити масштабування (наприклад, в Azure або AWS) і не переплачувати за потужності, що не використовуються.
4. Раннє виявлення аномалій
Багато проблем мають накопичувальний ефект. Витік пам’яті в додатку на Java або Python не обвалить сервер миттєво. Але моніторинг зафіксує плавне зростання споживання ресурсів і надішле повідомлення до того, як станеться “OOM Killer” (Out Of Memory).
5. Безпека та комплаєнс
Постійний аудит логів та мережевої активності допомагає виявити несанкціонований доступ. У контексті українського законодавства та вимог GDPR, захист персональних даних неможливий без контролю доступу до серверів у реальному часі.
Як працює моніторинг серверів: рівні та метрики
Ефективна система будується за принципом багатошарового пирога. Не можна дивитися тільки на “залізо”, ігноруючи бізнес-логіку.
Рівень 1: Інфраструктурний моніторинг
Тут ми стежимо за базовими показниками:
- CPU Load (Завантаження процесора): Чи є черги на обробку завдань?
- RAM (Оперативна пам’ять): Наскільки близька межа?
- Disk I/O та вільне місце: Забитий логами диск — найчастіша причина падіння баз даних.
- Network Traffic: Вхідний та вихідний трафік, затримки (latency).
Рівень 2: Мониторинг сервісів та БД
На цьому етапі перевіряється працездатність конкретних інструментів:
- Web-сервери (Nginx, Apache): Кількість активних з’єднань, час відповіді.
- Бази даних (PostgreSQL, SQL Server, Cosmos DB): Тривалість транзакцій, кількість заблокованих процесів.
- Черги (RabbitMQ, Redis): Довжина черги та швидкість обробки повідомлень.
Рівень 3: Application Performance Monitoring (APM)
Це найглибший рівень. Ми аналізуємо, як швидко виконується код самого додатка, які запити до БД найповільніші та на яких етапах користувач стикається з помилками 500.
Золоті сигнали моніторингу (Google SRE)
Якщо ви не знаєте, з чого почати, зосередьтеся на чотирьох “золотих сигналах”:
| Сигнал | Опис | Чому це важливо |
| Latency (Затримка) | Час, необхідний для обслуговування запиту. | Зростання затримки — перша ознака деградації сервісу. |
| Traffic (Трафік) | Попит на систему (HTTP запити/сек). | Допомагає зрозуміти навантаження та відрізнити реальних користувачів від ботів. |
| Errors (Помилки) | Частота запитів, які завершилися невдачею. | Дозволяє миттєво побачити баги після деплою. |
| Saturation (Насиченість) | Наскільки “повна” ваша система. | Показує, скільки ресурсів залишилося до критичної точки. |
Інструментарій для 24/7 підтримки серверів у 2026 році
Ринок пропонує десятки рішень. Вибір залежить від масштабу вашого проекту та бюджету.
1. Open Source рішення (Self-hosted)
- Zabbix: Універсальний комбайн. Чудово підходить для моніторингу фізичних серверів, мережевого обладнання та віртуальних машин на Linux/Ubuntu. Потребує глибокого налаштування.
- Prometheus + Grafana: Стандарт де-факто для хмарних середовищ та Kubernetes. Prometheus збирає метрики, а Grafana перетворює їх на красиві та зрозумілі дашборди.
- Netdata: Ідеально для моніторингу в реальному часі з точністю до секунди.
2. Хмарні інструменти (Cloud-Native)
Якщо ваш бізнес у хмарі, логічно використовувати вбудовані рішення:
- Azure Monitor: Глибока інтеграція з ресурсами Microsoft, моніторинг AKS, SQL Database та Entra ID.
- AWS CloudWatch: Потужний інструмент для екосистеми Amazon.
- Google Stackdriver: Оптимально для GCP.
3. SaaS-платформи (Enterprise рівень)
- Datadog: Лідер ринку APM. Дорого, але дає максимально повну картину “з коробки”.
- New Relic: Чудова візуалізація шляхів користувача та налагодження коду в реальному часі.
Організація процесу: Своя команда vs Аутсорсинг
Найскладніше питання для CTO: хто дивитиметься в монітори о 3 годині ночі в суботу?
Варіант А: Власний відділ моніторингу (NOC)
Щоб забезпечити покриття 24/7, вам потрібно як мінімум 4-5 співробітників (з урахуванням змін, відпусток та лікарняних).
- Плюси: Повний контроль, глибоке знання продукту.
- Мінуси: Величезні витрати на зарплати, податки та менеджмент.
Вариант Б: Чергування інженерів (On-call)
Розробники або DevOps-інженери по черзі беруть “тривожну кнопку”.
- Плюси: Економія.
- Мінуси: Вигорання співробітників, ризик того, що інженер не почує дзвінок вночі.
Вариант В: Аутсорсинг моніторингу 24/7
Передача функції спеціалізованій компанії.
- Плюси: Дешевше, ніж власний штат; гарантований час реакції за договором; наявність готових процесів.
- Мінуси: Потрібен час на передачу знань про архітектуру системи.
Моніторинг серверів в Україні: Специфіка та реалії 2026 року
Для українського бізнесу моніторинг сьогодні включає аспекти, про які рідко замислюються на Заході:
- Канали зв’язку: Моніторинг доступності через різних провайдерів та супутниковий зв’язок (Starlink).
- Енергонезалежність: Якщо ваш сервер стоїть “на місці”, необхідно моніторити стан ДБЖ та генераторів.
- Локальні ЦОД vs Хмари: Багато компаній мігрують з локальних дата-центрів до Європи (Польща, Німеччина) через Azure/AWS. Моніторинг допомагає контролювати затримки (latency) між українськими офісами та європейськими серверами.
FAQ: Часті питання
1. Чи достатньо просто налаштувати алерти в Telegram?
Для невеликого проекту — так. Для бізнесу — ні. Потрібна система управління інцидентами (наприклад, Opsgenie або PagerDuty), яка телефонуватиме, якщо повідомлення в месенджері проігноровано.
2. Чи впливає моніторинг на продуктивність сервера?
Правильно налаштований агент споживає менше 1-3% ресурсів CPU та RAM. Це мізерна плата за спокій.
3. З чого почати впровадження, якщо бюджету майже немає?
Встановіть Netdata для швидкого старту та UptimeRobot (безкоштовний рівень) для зовнішньої перевірки доступності сайту.
4. Чим моніторинг відрізняється від логування?
Метрики (моніторинг) говорять вам, що “системі погано”. Логи говорять вам, “чому саме їй погано”. Вам потрібно і те, і інше.
5. Чи потрібно моніторити тестові середовища (Staging)?
Так, це дозволяє виявити витоки ресурсів ще до того, як код потрапить у Production.
Висновок: Інвестуйте в стабільність
Моніторинг серверів 24/7 — це не лише про код та залізо. Це про спокій ваших клієнтів та передбачуваність вашого бізнесу. У світі, де конкуренція за увагу користувача йде на секунди, ви не можете дозволити собі бути “офлайн”.
Хочете переконатися, що ваша інфраструктура готова до будь-яких навантажень? Почніть з аудиту поточної системи моніторингу. Визначте критичні точки відмови та налаштуйте сповіщення вже сьогодні.
Потрібна допомога в налаштуванні професійного моніторингу? Наші експерти допоможуть розгорнути систему на базі Zabbix, Prometheus або Azure Monitor, адаптовану під потреби вашого бізнесу. Забезпечте своєму IT-департаменту спокійні ночі, а клієнтам — бездоганний сервіс!