Потенциал для автоматизации: избавляемся от рутинных процессов
Процессы разработки часто требуют много времени и очень рутинны. Они охватывают деливери разных фич или приложения от самой идеи до запуска на устройстве конечного пользователя. Однако, если идеи берут на себя продакт-менеджеры и сейлз-менеджеры, то мы их оцениваем и разрабатываем. И уже на этом этапе появляется большой потенциал для автоматизации, например процессов заливки кода и т.д. Это помогает сохранить время и усилия.nnОсновная идея автоматизации – непрерывная интеграция (Continuous Integration), объединяющая процессы тестирования, сборки и дополнительных проверок, а также непрерывная доставка (Continuous Delivery). Это то, что известно всем как CI/CD Pipeline девопс задача.nn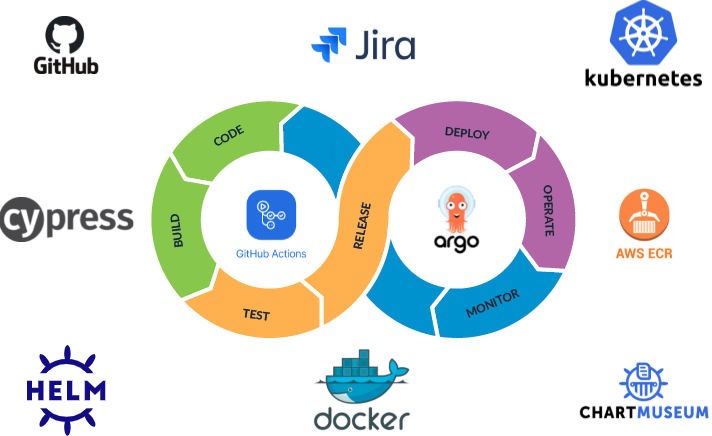 n
n
Что под капотом автоматизации
В CI/CD Pipeline разработка большинства современного ПО подразумевает итеративность:> Идея -> Написание кода -> Тестирование -> РелизnnЭтот процесс включает в себя значительное количество этапов, которые нужно повторять при прохождении каждого цикла. Автоматизировать этот процесс – одна из ключевых задач, когда проект расширяется. Это может быть связано как с увеличением команды разработчиков, так и с такими техническими особенностями, как рост количества сервисов в проекте или необходимость в параллельной разработке.n
Триггеры процессов.
Любые изменения в нашей инфраструктуре сопровождаются изменениями кода. То есть потенциальный разработчик берет последнюю версию программы, source code, меняет что-то, комит, заливает свой код на GitHub. Для нас это основной триггер для всех процессов автоматизации.n
1. Пишем код
По сути это этап генерации source code, который тесно связан с контролем версий, и здесь на помощь приходит Git. Используем GitHub для менеджмента репозиториев. Во многих из них разработка ведется параллельно и независимо, то есть разными командами.nnНастраивая свой CI/CD Pipeline, установили контракт для разработчиков при написании кода и заливке его в GitHub:1. Каждая созданная ветвь (Git) должна иметь в названии номер JIRA тикета. Так легко можно понять, к какой задаче относятся изменения в этой ветке. Эта информация также используется в следующих этапах нашего пайплайна (версионирование, деплой), поскольку каждая наша ветвь (тикет) развертывается как отдельная копия программы в отдельном окружении. Это позволяет вести действительно параллельную разработку множества фич одновременно и дать разработчикам свободу и независимость друг от друга.nn2. Каждый комит должен соответствовать стандарту Conventional Commits . Это облегчает создание Changelog, а также позволяет автоматически определять новую версию программы (о версии подробнее чуть позже)n
2. С source code в артефакт
Этап сборки программы включает все манипуляции для преобразования source code в артефакт:n
- Линтинг и статический анализ кода – проверяем код на соответствие нормам и внутренним правилам команды.
- Сборка (компиляция/контейнеризация) – здесь из исходного кода формируется единственный файл, которому будет назначена версия (процесс версионирования). После этого он попадет в реестр артефактов, то есть зарелизится.
- Тестирование – в зависимости от размера программы, здесь могут запускаться как юнит, так и в некоторых случаях интеграционные тесты.
Здесь в дело вступает GitHub Actions, как наш основной CI инструмент для автоматизации.n
3. SemVer для всех артефактов: получаем валидную версию
На этом этапе артефакта назначается версия. Используем SemVer для всех типов наших артефактов. В этом деле нам помогает Semantic Release и Conventional Commits. Они позволяют в несколько строк кода решить задачу версионирования и получить на выходе актуальную и валидную версию.nnКак вы помните, каждая наша git-ветка развертывается как отдельная копия программы и имеет в своем имени номер JIRA тикета. Этот номер используется как пререлиз токена при формировании версии, а также как сабдомен при развертывании программы.n
4. Выпускаем релиз в свет
Здесь мы загружаем наш артефакт в соответствующий реестр. У нас это:Docker Image → Amazon ECRnHelm Chart → ChartMuseumnNPM Package → GitHub Packagesn
5. Деплой: следим за правильностью работы
Происходит развертывание программы и в дело вступает ArgoCD . Работает это так:ArgoCD следит за изменениями в одном из наших git-репозиториев (argo) и ждет, когда там появится или изменится Helm Chart (конфигурация) с описанием всех зависимостей и их версий (то, что было сформировано на этапе релиза), необходимых в этом окружении. В этой репозитории также живет базовый шаблон такого чарта с дефолтными настройками и версиями, необходимыми для запуска базовой версии программы.nnЗдесь также хранится Triggerable GH Action, который можно запустить с использованием обычного curl. Ему можно передать названия и версии зависимостей, которые вы хотите переопределить в шаблоне, после чего небольшой скрипт измерит базовый шаблон (chart.yml) с переданными вами версиями, создаст новый Helm Chart именно под ваши потребности в папке с именем того же JIRA тикета . Его подхватит ArgoCD и самостоятельно задеплоит в Kubernetes.nnЗа всем вы можете наблюдать с веб-консоли ArgoCD в приятном графическом интерфейсе, просматривать логи при необходимости и следить за правильностью работы вашей версии программы.n
6. Переходим к тестированию
После полноценного развертывания программы или ее копии у нас производится запуск E2E тестов. Мы используем Cypress, поэтому просто запускаем наши тесты в GH Actions через Triggerable Pipeline (вызов curl из k8s джоба). А также автоматически прикрепляем ссылку на развернутое приложение к JIRA Тикету, чтобы мануальные тестировщики быстро могли приступить к тестированию.nnПосле всех проверок и апрувов код мержится в master (production ready ветвь). И весь процесс происходит еще раз, однако теперь доставка осуществляется уже в продакшне, после чего результат работы может наблюдать конечный пользователь.nnВ общем, весь пайплайн занимает от 3 до 7 минут в среднем. А количество развернутых копий программы напрямую зависит от количества разработчиков и задач на борде. В общей сложности у нас одновременно запущено около 80 копий. Приложения, не переживающие редеплой в течение семи дней, автоматически умирают, однако в любой момент могут быть перезапущены заново.n
Масштабирование и микросервисная архитектура: суммируем результаты
При этом подход непрерывной доставки важен для любой команды. Если пишешь под Android, будут свои нюансы, например, отправляешь все в Play Market, а мы – на сервер. Однако суть одна. Мы, как команда Back-end Core, пытались задать общий вектор именно нашей микросервисной архитектуры. Ведь сейчас мы в процессе перехода от монолитной архитектуры, которая у нас была в прошлом, к независимой интеграции и доставке микросервисной архитектуры.