ИТ-система, как и любая другая сложная структура имеет свой ресурс надежности и устойчивости к старению. Причин множество, и перечислять их слишком долго — тут и появление новых рисков, спровоцированное развитием сферы малваре, и естественное старение «железа», и недостатки проектирования.
На уровне физической структуры повышение отказоустойчивости обеспечивается снижением зависимости качества работы приложений от сбоев и отказов сервера. А обеспечить отказоустойчивость сервера можно с помощью избыточности, назначая каждому компоненту резервную копию. Именно такой резерв оперативно берет на себя нагрузку в случае выхода из строя основного ресурса.
Избыточность, и как ее достичь
Единственный способ избежать отказа системы — избавиться от «единых» точек отказа» (SPOF). Практика управления инфраструктурами всех уровней и масштабов доказывает, что избыточность — единственный путь к такому решению, поскольку обеспечивает резервирование абсолютно всех компонентов. Логично, ведь вероятность одновременного сбоя 2-х серверов намного меньше, чем одного.
При этом резервы должны в мельчайших деталях копировать конфигурации основных компонентов (количество «оперативки», функциональные характеристики процессоров и прочее).
Какие подходы практикуются для резервирования веб-компонентов:
- Дублирование NS-записей.
- Резервирование фронтендов.
- Оптимизация числа бекендов.
- Резервирование баз данных.
Дублирование NS-записей
Как правило, для каждого домена назначается несколько NS-записей.

Если один из серверов «падает», его запросы начинают обрабатывать другие машины.
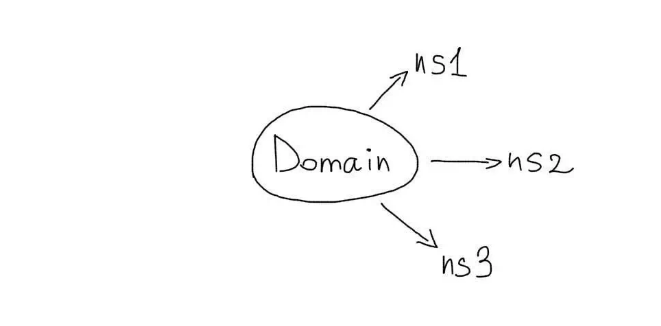
Соответственно, запросы обеспечиваются гарантированно высоким уровнем доступности. Вот и весь секрет отказоустойчивости сети с помощью DNS. А убедиться, что домен получил несколько NS-записей, можно с помощью команды:
Соответственно, запросы обеспечиваются гарантированно высоким уровнем доступности. Вот и весь секрет отказоустойчивости сети с помощью DNS.
Резервирование фронтендов
Сбои и неполадки на линии серверов, которые обеспечивают получение клиентских запросов и ответы на них, грозят недоступностью веб-приложения целиком.
Чтобы избежать этого проводят резервирование фронтендов при участии виртуальных IP-адресов UCARP. Вследствие процедуры один из серверов получает виртуальный АйПи с привязанным к нему доменом. При неполадках на основном сервере дублирующий АйПи-адрес привязывается к резервной машине.
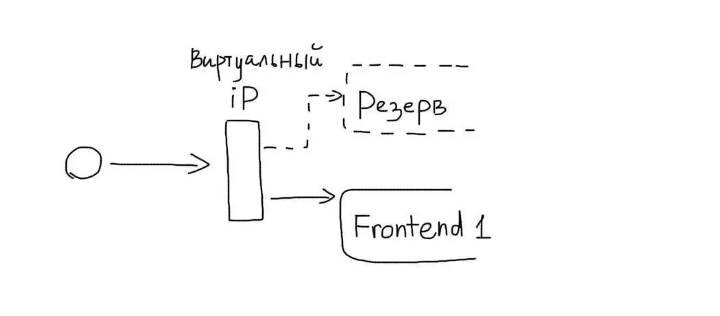
Автоматизация отслеживания состояний и переключения IP-адреса позволит ежесекундно опрашивать основной ресурс и выявлять степень корректности его действий (так называемый heartbeat). При отсутствии корректной реакции, IP-адрес делегируется фронтенду.
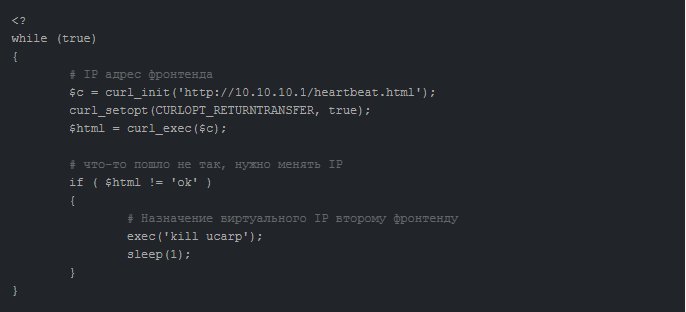
Упрощенный мониторинг доступности и отказоустойчивости сервера UCARP обеспечивает самостоятельно.
Оптимизация числа бекендов
Идентичность серверов, обеспечивающих работу основного приложения позволяет применить активное резервирование. То есть, в обработке запросов задействуются все бекенды, без резерва. Как только один из них сбоит, он автоматически «выпадает» из списка, а фронтенд перестает подавать на него запросы. Однако такая последовательность грозит повышением нагрузки на остальные серверы.
Чтобы гарантировать повышение отказоустойчивости, следует рассчитывать количество бекендов исходя из предпосылки, что в любую секунду под угрозой может оказаться 25% их числа.
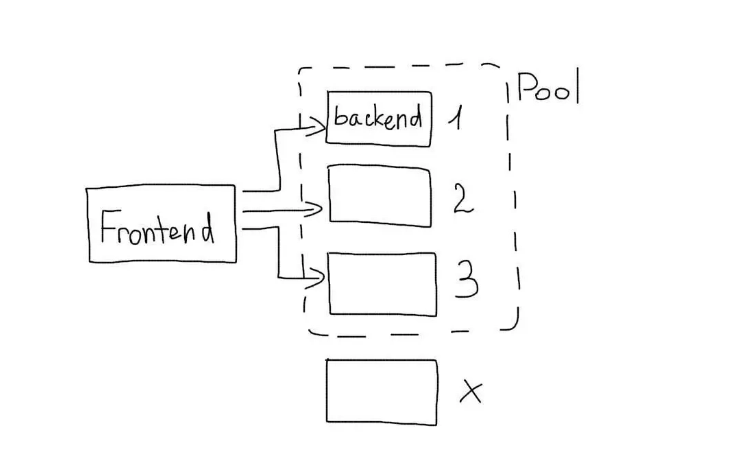
Назначение нескольких серверов с целью обработки fastcgi-запросов при помощи upstream происходит с участием Nginx. Распределение запросов между серверами производится в автоматическом режиме.
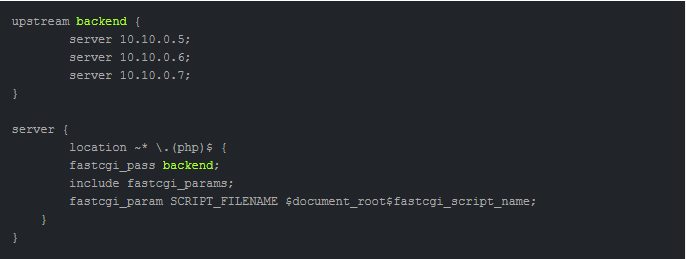
Также Nginx анализирует ошибки, содержащиеся в ответах бекендов, в реальном времени. Если ошибка обнаружена — отправка запросов на вышедший из строя бекенд приостанавливается. Тайминг и число попыток настраиваются.
Резервирование баз данных
Эта задача считается наиболее сложной в рамках повышения отказоустойчивости сети. Обычно для этого применяется репликация, в ходе которой выделяется главный сервер для БД (Мастер), отвечающий за модификацию данных. Вспомогательный сервер (Слейв) копирует все изменения, которые происходят на мастер-сервере и отвечает за их чтение.
Основной особенностью таких реплик является работа в пассивном режиме, без обработки запросов от приложений. Задача реплики — хранение актуальной копии БД с Мастера.
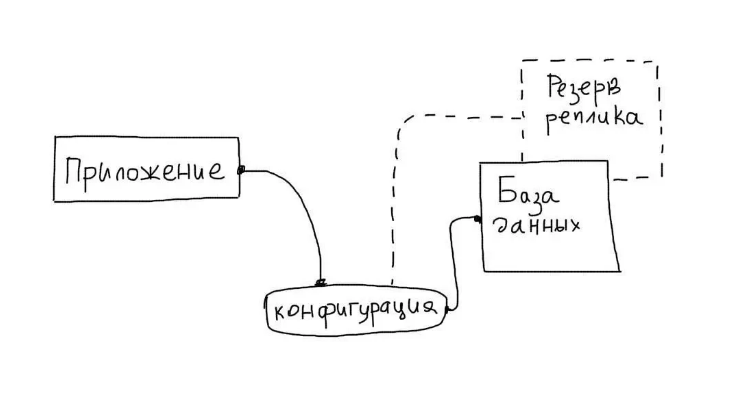
Преимуществом подхода является удобная автоматизация процессов отслеживания состояния БД. Если обнаруживается ошибка, приложение автоматически изменяет настройки и «подключает» к работе сервер-репликант.
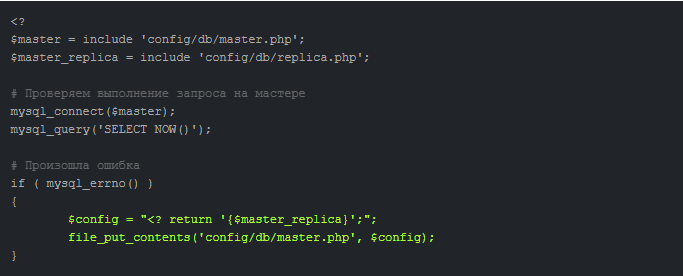
Восстановление вышедшего из строя сервера происходит следующим образом:
- Сервер отключается.
- Производится восстановление на физическом уровне.
- Проводится настройка и синхронизация реплики с дублирующего сервера.
- В приложении прописывается конфигурация рабочего дубль-сервера.
Слейв-сервер настраивается с Мастер-сервера при участии утилиты Xtrabackup.
Затем бывший Слейв переходит в статус Мастера, а восстановленный сервер превращается в резервный (Слейв).
Дельный совет
Как уже было сказано в начале статьи, каждому серверу рано или поздно грозит поломка или сбой. Поэтому главной заповедью повышения отказоустойчивости является сведение к нулю количества компонентов, работающих в единственном экземпляре. Для этого и применяется резервирование.
Планируя масштабирование системы, выделите ресурсы для приобретения резервного оборудования. Поскольку мировой опыт многократно доказывает, что полезнее использовать менее мощные сервера в большом количестве, чем наоборот.
Для вас мы можем быстро и с гарантией повысить отказоустойчивость ИТ инфраструктуры. Свяжитесь с нами.