В условиях современной цифровой экономики, где каждая минута простоя сайта или корпоративного приложения конвертируется в тысячи долларов убытков и потерю репутации, мониторинг серверов перестает быть просто «технической задачей». Сегодня это стратегическая необходимость. Если ваша инфраструктура недоступна, для клиента вашего бизнеса просто не существует.
Для CTO, IT-директоров и владельцев растущих компаний в Украине вопрос стабильности стоит особенно остро. Учитывая миграцию в облака (Azure, AWS, GCP) и гибридные модели работы, 24/7 поддержка серверов становится фундаментом, на котором строится доверие пользователей.
В этой статье мы глубоко разберем, как работает современный мониторинг, какие метрики критичны для бизнеса и как построить систему, которая предупреждает проблему до того, как ее заметит клиент.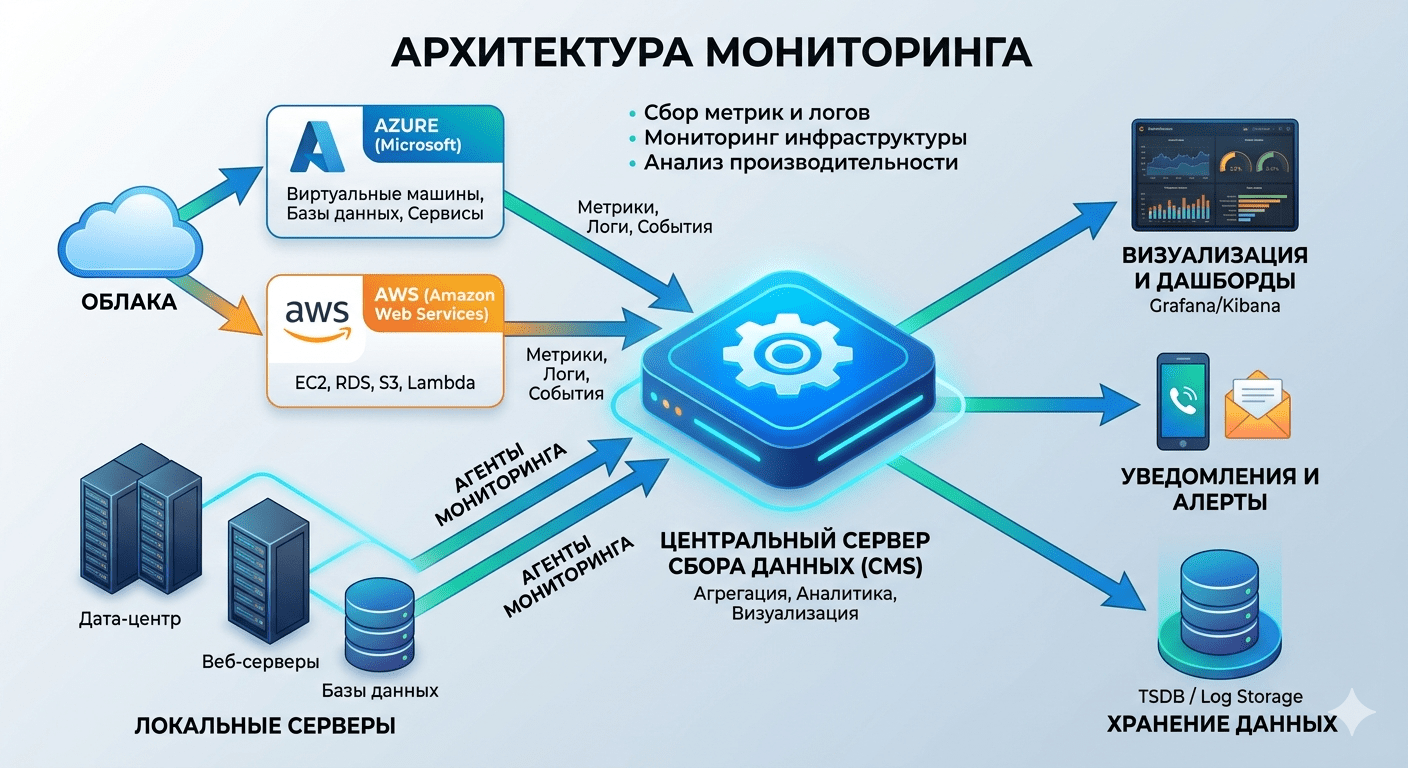
Что такое мониторинг серверов и почему «проверки раз в час» больше не работают
Мониторинг серверов — это процесс непрерывного сбора, анализа и визуализации данных о состоянии аппаратного и программного обеспечения. Это «пульс» вашей IT-системы.
Раньше системным администраторам было достаточно периодически проверять доступность сервера по PING. В 2026 году этого катастрофически мало. Современное приложение — это сложная экосистема микросервисов, баз данных и внешних API. Если сервер «пингуется», это не значит, что пользователи могут совершить покупку.
Почему 24/7 — это стандарт, а не роскошь?
- Глобализация: Ваши клиенты могут находиться в разных часовых поясах.
- Сложность инфраструктуры: Контейнеризация (Kubernetes/AKS) требует мгновенной реакции на падение подов.
- Безопасность: Подозрительные всплески трафика ночью могут быть признаком начала DDoS-атаки или попытки взлома.
Зачем бизнесу нужен круглосуточный мониторинг: 5 ключевых причин
1. Минимизация убытков от простоев (Downtime)
Согласно исследованиям Gartner, средняя стоимость часа простоя ИТ-систем для крупного бизнеса составляет около $300,000. Для среднего бизнеса в Украине цифры скромнее, но не менее болезненны. Круглосуточный мониторинг позволяет сократить время реакции (MTTR — Mean Time To Recovery) с часов до минут.
2. Соблюдение SLA (Service Level Agreement)
Если вы предоставляете услуги другим компаниям, в вашем контракте наверняка прописан аптайм (например, 99.9%). Без системы контроля 24/7 вы не сможете гарантировать выполнение этих обязательств и рискуете получить штрафные санкции.
3. Оптимизация ресурсов и планирование бюджета
Мониторинг показывает не только ошибки, но и нагрузку. Вы видите, когда процессор загружен на 90%, а когда память простаивает. Это позволяет вовремя проводить масштабирование (например, в Azure или AWS) и не переплачивать за неиспользуемые мощности.
4. Раннее обнаружение аномалий
Многие проблемы имеют накопительный эффект. Утечка памяти в приложении на Java или Python не обрушит сервер мгновенно. Но мониторинг зафиксирует плавный рост потребления ресурсов и отправит уведомление до того, как произойдет «OOM Killer» (Out Of Memory).
5. Безопасность и комплаенс
Постоянный аудит логов и сетевой активности помогает выявить несанкционированный доступ. В контексте украинского законодательства и требований GDPR, защита персональных данных невозможна без контроля доступа к серверам в реальном времени.
Как работает мониторинг серверов: уровни и метрики
Эффективная система строится по принципу многослойного пирога. Нельзя смотреть только на «железо», игнорируя бизнес-логику.
Уровень 1: Инфраструктурный мониторинг
Здесь мы следим за базовыми показателями:
- CPU Load (Загрузка процессора): Есть ли очереди на обработку задач?
- RAM (Оперативная память): Насколько близок предел?
- Disk I/O и свободное место: Забитый логами диск — самая частая причина падения баз данных.
- Network Traffic: Входящий и исходящий трафик, задержки (latency).
Уровень 2: Мониторинг сервисов и БД
На этом этапе проверяется работоспособность конкретных инструментов:
- Web-серверы (Nginx, Apache): Количество активных соединений, время ответа.
- Базы данных (PostgreSQL, SQL Server, Cosmos DB): Длительность транзакций, количество заблокированных процессов.
- Очереди (RabbitMQ, Redis): Длина очереди и скорость обработки сообщений.
Уровень 3: Application Performance Monitoring (APM)
Это самый глубокий уровень. Мы анализируем, как быстро исполняется код самого приложения, какие запросы к БД самые медленные и на каких этапах пользователь сталкивается с ошибками 500.
Золотые сигналы мониторинга (Google SRE)
Если вы не знаете, с чего начать, сфокусируйтесь на четырех «золотых сигналах»:
| Сигнал | Описание | Почему это важно |
| Latency (Задержка) | Время, необходимое для обслуживания запроса. | Рост задержки — первый признак деградации сервиса. |
| Traffic (Трафик) | Спрос, предъявляемый к системе (HTTP запросы/сек). | Помогает понять нагрузку и отличить реальных пользователей от ботов. |
| Errors (Ошибки) | Частота запросов, которые завершились неудачей. | Позволяет мгновенно увидеть баги после деплоя. |
| Saturation (Насыщенность) | Насколько «полна» ваша система. | Показывает, сколько ресурсов осталось до критической точки. |
Инструментарий для 24/7 поддержки серверов в 2026 году
Рынок предлагает десятки решений. Выбор зависит от масштаба вашего проекта и бюджета.
1. Open Source решения (Self-hosted)
- Zabbix: Универсальный комбайн. Отлично подходит для мониторинга физических серверов, сетевого оборудования и виртуальных машин на Linux/Ubuntu. Требует глубокой настройки.
- Prometheus + Grafana: Стандарт де-факто для облачных сред и Kubernetes. Prometheus собирает метрики, а Grafana превращает их в красивые и понятные дашборды.
- Netdata: Идеально для мониторинга в реальном времени с точностью до секунды.
2. Облачные инструменты (Cloud-Native)
Если ваш бизнес в облаке, логично использовать встроенные решения:
- Azure Monitor: Глубокая интеграция с ресурсами Microsoft, мониторинг AKS, SQL Database и Entra ID.
- AWS CloudWatch: Мощный инструмент для экосистемы Amazon.
- Google Stackdriver: Оптимально для GCP.
3. SaaS-платформы (Enterprise уровень)
- Datadog: Лидер рынка APM. Дорого, но дает максимально полную картину «из коробки».
- New Relic: Отличная визуализация путей пользователя и отладка кода в реальном времени.
Организация процесса: Своя команда vs Аутсорсинг
Самый сложный вопрос для CTO: кто будет смотреть в мониторы в 3 часа ночи в субботу?
Вариант А: Собственный отдел мониторинга (NOC)
Чтобы обеспечить покрытие 24/7, вам нужно как минимум 4-5 сотрудников (с учетом смен, отпусков и больничных).
- Плюсы: Полный контроль, глубокое знание продукта.
- Минусы: Огромные затраты на зарплаты, налоги и менеджмент.
Вариант Б: Дежурства инженеров (On-call)
Разработчики или DevOps-инженеры по очереди берут «тревожную кнопку».
- Плюсы: Экономия.
- Минусы: Выгорание сотрудников, риск того, что инженер не услышит звонок ночью.
Вариант В: Аутсорсинг мониторинга 24/7
Передача функции специализированной компании.
- Плюсы: Дешевле, чем свой штат; гарантированное время реакции по договору; наличие готовых процессов.
- Минусы: Требуется время на передачу знаний об архитектуре системы.
Мониторинг серверов в Украине: Специфика и реалии 2026 года
Для украинского бизнеса мониторинг сегодня включает аспекты, о которых редко задумываются на Западе:
- Каналы связи: Мониторинг доступности через разных провайдеров и спутниковую связь (Starlink).
- Энергонезависимость: Если ваш сервер стоит «на месте», необходимо мониторить состояние ИБП и генераторов.
- Локальные ЦОД vs Облака: Многие компании мигрируют из локальных дата-центров в Европу (Польша, Германия) через Azure/AWS. Мониторинг помогает контролировать задержки (latency) между украинскими офисами и европейскими серверами.
FAQ: Часто задаваемые вопросы
1. Достаточно ли просто настроить алерты в Telegram?
Для небольшого проекта — да. Для бизнеса — нет. Нужна система управления инцидентами (например, Opsgenie или PagerDuty), которая будет звонить на телефон, если сообщение в мессенджере проигнорировано.
2. Влияет ли мониторинг на производительность сервера?
Правильно настроенный агент потребляет менее 1-3% ресурсов CPU и RAM. Это ничтожная плата за спокойствие.
3. С чего начать внедрение, если бюджета почти нет?
Установите Netdata для быстрого старта и UptimeRobot (бесплатный уровень) для внешней проверки доступности сайта.
4. Чем мониторинг отличается от логирования?
Метрики (мониторинг) говорят вам, что «системе плохо». Логи говорят вам, «почему именно ей плохо». Вам нужно и то, и другое.
5. Нужно ли мониторить тестовые среды (Staging)?
Да, это позволяет выявить утечки ресурсов еще до того, как код попадет в Production.
Заключение: Инвестируйте в стабильность
Мониторинг серверов 24/7 — это не только про код и железо. Это про спокойствие ваших клиентов и предсказуемость вашего бизнеса. В мире, где конкуренция за внимание пользователя идет на секунды, вы не можете позволить себе быть «оффлайн».
Хотите убедиться, что ваша инфраструктура готова к любым нагрузкам? Начните с аудита текущей системы мониторинга. Определите критические точки отказа и настройте уведомления уже сегодня.
Нужна помощь в настройке профессионального мониторинга? Наши эксперты помогут развернуть систему на базе Zabbix, Prometheus или Azure Monitor, адаптированную под нужды вашего бизнеса. Обеспечьте своему IT-департаменту спокойные ночи, а клиентам — безупречный сервис!