В предыдущей статье мы говорили о необходимости мониторинга docker swarm и как его настроить. В продолжение статьи рассмотрим как настроить grafana.
Когда сервисы развернуты, вы можете открыть grafana с IP любого узла в swarm. Мы откроем IP-адрес менеджера следующей командой.
open http://`docker-machine ip manager`
По умолчанию используйте логин admin и пароль для входа в grafana. Первое, что нужно сделать в grafana, — добавить InfluxDB в качестве источника данных. На домашней странице должна быть ссылка « Create your first data source, нажмите на нее. Если ссылка не видна, вы можете выбрать в меню Источники Add data source и выбрать пункт Add data source . Появится форма для добавления нового источника данных.
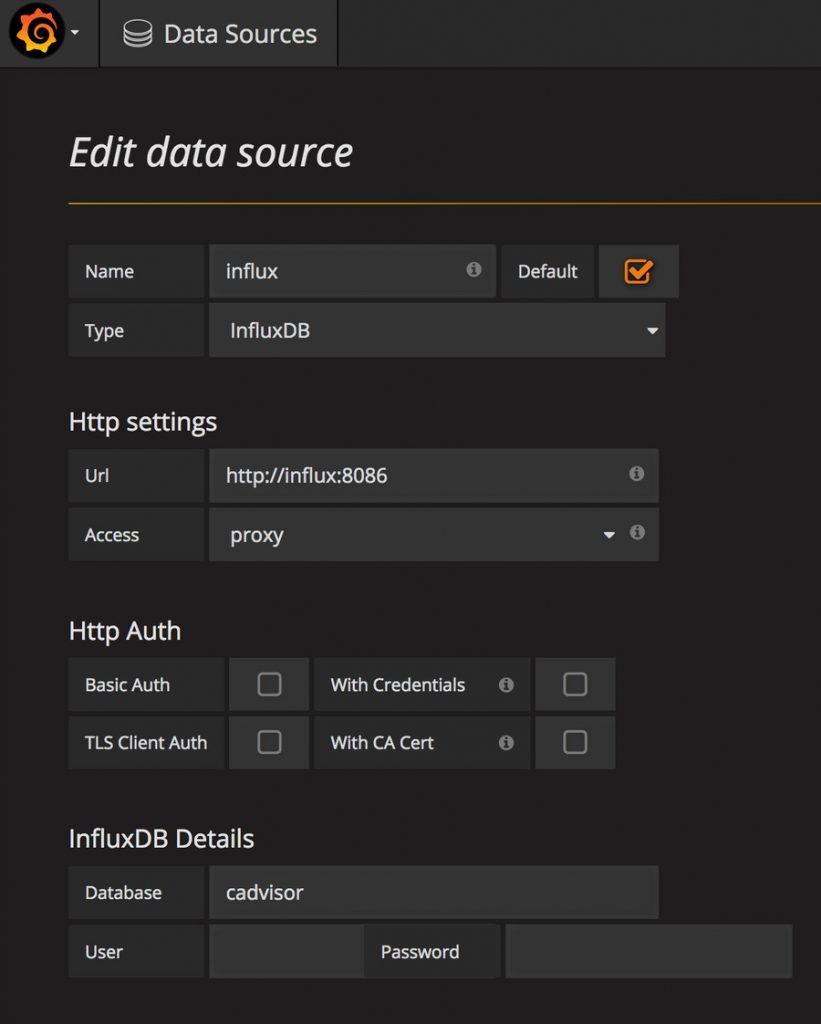
Вы можете указать любое имя для источника. Отметьте поле по умолчанию, чтобы вам не пришлось упоминать источник данных повсюду. Выберите тип в качестве InfluxDB . Теперь URL-адрес http://influx:8086 и Access укажите proxy . Это укажет на порт, прослушиваемый контейнером InfluxDb. Наконец, укажите Базу данных cadvisor и нажмите кнопку Save and Test . В результате должны получить Data source is working .
В репозитории github файл dashboard.json , который можно импортировать в Grafana. Это обеспечит приборную панель, которая контролирует системы и контейнеры, работающие в swarm. Сейчас мы импортируем панель инструментов и поговорим об этом в следующем разделе. В меню наведите на Dashboards и выберите параметр « Import Option . Нажмите кнопку « Upload .json file » и выберите файл dashboard.json . Выберите источник данных и нажмите кнопку « Import », чтобы импортировать эту панель.
Панель инструментов Grafana
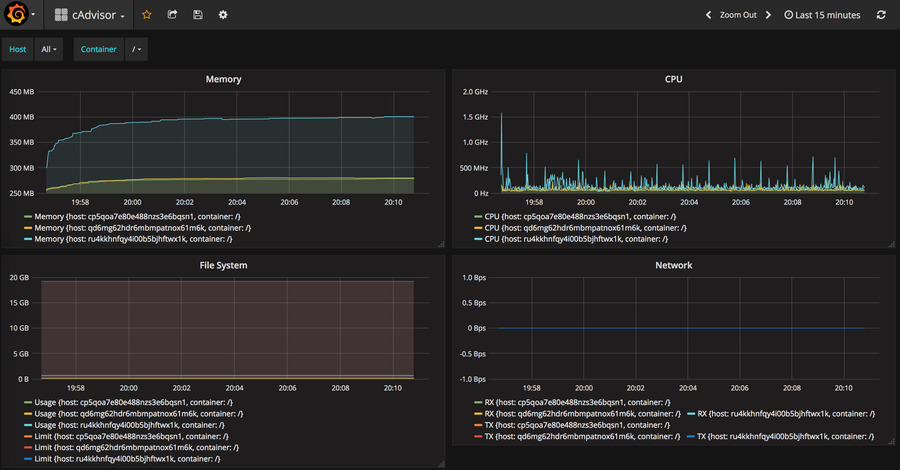
Приборная панель, импортированная в Grafana, будет контролировать хост и контейнеры в swarm. Вы можете перейти на уровень хоста и даже до уровня контейнера на каждом узле. Чтобы иметь возможность сделать это, мы используем две переменные. Чтобы добавить переменные в панель инструментов Grafana, мы используем функцию шаблонов. Есть две переменные, host для выбора узла и container для выбора контейнера. Чтобы увидеть переменные, выберите «Настройки» на странице информационной панели и выберите « Templating .
Первая переменная — это host дает возможность выбрать узел и перейти к его метрикам. Когда cAdvisor отправляет показатели InfluxDB, он также включает некоторые теги, которые мы будем использовать для фильтрации показателей. Существует тег с именем machine который показывает имя хоста экземпляра cAdvisor. В этом случае он будет соответствовать идентификатору хостов в swarm. Чтобы получить значения в теге, мы выполним show tag values with key = "machine" в качестве запроса.
Вторая переменная — это container а это значит, что необходимо перейти к метрикам уровня контейнера.container_name тег с именем container_name который содержит имя контейнера. Нам также нужно получить только значения, основанные на значении переменных host . Таким образом, запрос show tag values with key = "container_name" WHERE machine =~ /^$host$/ . Это выберет контейнеры, которые запущены в узле, выбранном переменной host .
Имя контейнера будет выглядеть примерно так: monitor_cadvisor.y78ac29r904m8uy6hxffb7uvn.3j231njh03spl0j8h67z069cy . Тем не менее, нас интересует только часть monitor_cadvisor . Если есть несколько экземпляров одной и той же службы, нам нужны отдельные строки. Чтобы /([^.]+)/ отделить часть, мы используем/([^.]+).
Теперь, когда создали переменные, мы можем использовать их в графиках. Обсудим график Memory а остальные аналогичны. Значения памяти memory_usage серии memory_usage в InfluxDB, поэтому запрос начинается с SELECT "value" FROM "memory_usage" .
Теперь мы добавляем фильтры с ключевым словом WHERE . Первое условие состоит в том, что machine равна переменной host . Т.е. "machine" =~ /^$host$/ . Второе условие заключается в том, что container_name с container . Это задается с помощью "container_name" =~ /^$container$*/ . Заключительным условием является совпадение временного интервала, $timeFilter в приборной панели grafana, $timeFilter . Запрос теперь SELECT "value" FROM "memory_usage" WHERE "container_name" =~ /^$container$*/ AND "machine" =~ /^$host$/ AND $timeFilter .
Поскольку нам нужны отдельные строки для разных хостов и контейнеров, вам нужно сгруппировать данные на основе тегов machine и container_name . Теперь весь запрос будет: SELECT "value" FROM "memory_usage" WHERE "container_name" =~ /^$container$*/ AND "machine" =~ /^$host$/ AND $timeFilter GROUP BY "machine", "container_name" .
Также Memory {host: $tag_machine, container: $tag_container_name} для этого запроса как Memory {host: $tag_machine, container: $tag_container_name} . Здесь $tag_machine будет заменено $tag_machineв machine теге, а tag_container_name будет заменено container_name теге container_name . Остальные графики похожи. Изменяется только название серии. Вы также можете создавать предупреждения для этих показателей из Grafana.
Вывод
В этой статье мы смогли настроить масштабируемое решение для мониторинга для Docker Swarm, которое автоматически контролирует все хосты и контейнеры, запущенные в swarm. При этом мы познакомились с популярными инструментами с открытым исходным кодом, такими как Grafana, InfluxDB и cAdvisor.
Если Вам необходима подобная система или обслуживание docker swarm, обращайтесь office@itfb.com.ua