Здесь приведены жестко заданные предположения, используемые оптимизатором в рамках метода «оптимизация для неизвестного». По крайней мере, в этом случае вы знаете, как оптимизатор угадывает неизвестные величины. Оптимальная настройка запросов в значительной мере начинается с умения объяснить оценки числа строк, особенно неточные. В моих примерах запросы будут направлены к таблице Sales. SalesOrderDetail в тестовой базе данных AdventureWorks2014. Если вы захотите выполнить примеры из этой статьи, но не располагаете установленной базой данных, ее можно загрузить. Кроме того, стоит убедиться, что база данных настроена на уровень совместимости 120, при котором SQL Server по умолчанию использует новое средство СЕ (2014). Сделать это можно с помощью следующего программного кода:— Убедитесь, что уровень совместимости базы данных >= 120nдля использования по умолчанию нового средства СЕn
USE AdventureWorks2014; nnGO nnIF (SELECT compatibilityjevel FROM sys. databases WHERE name = N'AdventureWorks2014')<120nnALTER DATABASE AdventureWorks2014 SET COMPATIBILITYJ.EVEL = 120; -- использование уровня 130 в 2016
Оценки оптимизации для неизвестных я разделяю на следующие группы операторов:n
* >, >=, <, <= "BETWEEN и LIKE
В первом разделе, в котором рассматривается первая группа операторов, показаны различные сценарии использования метода оптимизации для неизвестного. В следующих разделах для демонстрации оценок используется один или два сценария.nnОптимизация для неизвестного для операторов: >, >=, <, <=nОценка с оптимизацией для неизвестного для группы операторов >, >=, < и <= составляет 30% количества элементов ввода. Это относится как к новому средству СЕ (2014), так и к старому (7.0). Например, предположим, вы направляете запрос к таблице Sales.SalesOrderDetail в базе данных AdventureWorks20I4 и используете фильтр, такой как WHERE OrderQty >= <неизвестный_ввод>. Число строк в таблице 121 317, поэтому СЕ фильтра будет 0,3 * 121317 = 36395,1. Насколько эта величина близка к действительному числу строк в типичном варианте использования, решать вам; однако оптимизатор делает именно такое предположение.nЭто первый раздел, в котором демонстрируется метод оптимизации для неизвестного, поэтому начнем с перечисления различных случаев использования данного метода наряду с готовыми к применению примерами. Метод оптимизации для неизвестного используется в следующих случаях.n
Оптимальная настройка запросов начинается с умения объяснить оценки числа строк, особенно неточные
1. При работе с локальными переменнымиnВ отличие от значений параметров, которые можно прослушивать, значения переменных обычно прослушать нельзя. Исключение будет описано немного позже. Причина проста: начальная единица оптимизации — весь пакет, а не только инструкция запроса. Объявление и задание значений переменным выполняются в оптимизируемом пакете. Точка, в которой запрос оптимизируется, предшествует заданию любой переменной, поэтому значения переменных нельзя прослушивать. В результате оптимизатору приходится использовать метод оптимизации для неизвестного.nnЧтобы сравнить метод оптимизации для неизвестного с естественным методом оптимизации для известного, рассмотрим следующий запрос, имеющий предикат фильтра с оператором >= и известную константу в качестве входных данных:n
SELECT ProductID, COUNT (*) AS NumOrdersnFROM Sales.SalesOrderDetaiinWHERE OrderQty >= 40nnGROUP BY ProductID;
План выполнения для этого запроса показан на рисунке 1. Классический инструмент, используемый оптимизатором, чтобы получить СЕ для фильтра, — гистограмма. Если ее не существовало для столбца OrderQty перед выполнением этого запроса и вы не отключили автоматическое создание статистики в базе данных, то SQL Server создает ее при выполнении запроса. Вы можете использовать запрос, приведенный в листинге, чтобы получить автоматически созданное имя статистики.nnВыполнив этот программный код после предшествующего запроса, я получил имя статистики _ WA_Sys_00000004_44 СА3770. Запомните полученное вами имя. Затем используйте следующий код для просмотра гистограммы после замены имени статистики на полученное вами:n
DBCC SHOW STATISTICSn(N 'Sales.SalesO rderDetai I N'_WA_Sys_00000004_44CA3770)nWITH HISTOGRAM;
 nnТаблица Последние несколько шагов гистограммыn
nnТаблица Последние несколько шагов гистограммыn
| RANGE_HI_KEY | RANGE ROWS | ECLROWS | DISTINCT RANGE ROWS | AVG_RANGE_ROWS |
| 38 | 0 | 1 | 0 | 1 |
| 39 | 0 | 1 | 0 | 1 |
| 40 | 0 | 2,006392 | 0 | 1 |
| 41 | 0 | 1 | 0 | 1 |
| 44 | 0 | 1 | 0 | 1 |
n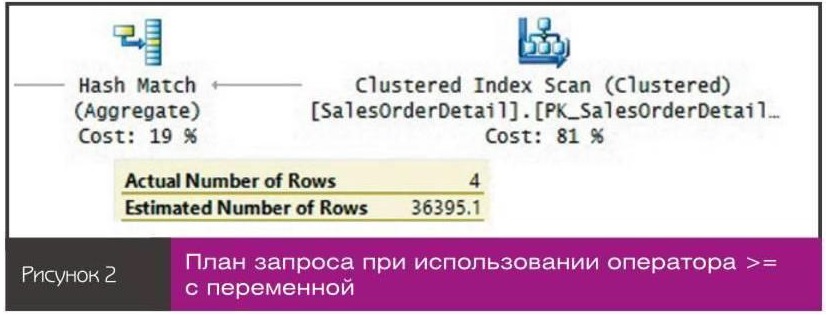 nnПоследние несколько шагов в полученной гистограмме показаны в таблице 1.nМы ясно видим, что СЕ, показанная на рисунке 1, основана на последних трех шагах гистограммы. Оценка довольно точная: 4,00639 при действительном значении 4. В отличие от приведенного выше примера, в следующем запросе используется локальная переменная, что вынуждает оптимизатор применить метод оптимизации для неизвестного:n
nnПоследние несколько шагов в полученной гистограмме показаны в таблице 1.nМы ясно видим, что СЕ, показанная на рисунке 1, основана на последних трех шагах гистограммы. Оценка довольно точная: 4,00639 при действительном значении 4. В отличие от приведенного выше примера, в следующем запросе используется локальная переменная, что вынуждает оптимизатор применить метод оптимизации для неизвестного:n
DECLARE @Qty AS INT = 40;nSELECT ProductID, COUNT (*) AS NumOrdersnFROM Sales.SalesOrderDetailnWHERE OrderQty >=@QtynGROUP BY ProductID;
План для этого запроса показан на рисунке 2.nnКак было предсказано, это оценка 30% количества элементов ввода. Примечательно, что из-за неточности оценки оптимизатор выбрал неоптимальную стратегию статистической обработки. Здесь использован алгоритм статистической обработки Hash Match вместо сортировки и алгоритма Stream Aggregate. Это лишь одно из многих возможных последствий неточных оценок. Существует исключение, при котором оптимизатор может прослушивать переменные: событие перекомпиляции происходит на уровне инструкций. Дело в том, что по определению перекомпиляция на уровне инструкций происходит после того, как выполнено задание всех переменных. Автоматическая перекомпиляция всегда происходит на уровне инструкций. Так было все время после появления SQL Server 2005 и до написания данной статьи. Я тестирую программный код на SQL Server 2016. Для ручной перекомпиляции на уровне инструкций нужно добавить указание запроса RECOMPILE с использованием оператора OPTION:n
DECLARE @Qty AS INT = 40;nSELECT ProductID, COUNT AS NumOrdersnFROM Sales.SalesOrderDetailnWHERE OrderQty >=@QtynGROUP BY ProductIDnOPTION (RECOMPILE);
Этот запрос формирует такой же план, как показанный на рисунке 1, где оценка является точной. Обратите внимание, что если указать параметр WITH RECOMPILE на уровне процедуры, то прослушивание не будет включено — это достигается только указанием в запросе OPTION (RECOMPILE). Перейдем к следующему случаю использования метода оптимизации для неизвестного.nn2. При использовании параметров, но отключенном автоматическом прослушивании параметров с указанием OPTIMIZE FOR UNKNOWN или OPTIMIZE FOR (©parameter UNKNOWN) или с флагом трассировки 4136nОбычно значения параметров доступны для прослушивания, так как они задаются при выполнении процедуры или функции, прежде чем пакет передается оптимизатору. Однако можно применить метод оптимизации для неизвестного с двумя указаниями запроса. Если нужно отменить прослушивание параметров для всех входов, используйте указание OPTIMIZE FOR UNKNOWN. Если требуется отменить прослушивание для определенного параметра, используйте указание OPTIMIZE FOR (©parameter UNKNOWN). Также можно использовать флаг трассировки 4136 для отключения прослушивания параметров при разных детализациях: запроса, сеанса или глобальной детализации. Обратите внимание, что при использовании хранимой процедуры, скомпилированной в собственном коде, оптимизация для неизвестного выбирается по умолчанию. В качестве примера следующий программный код создает хранимую процедуру и отключает прослушивание параметров в запросе с использованием указанияn
OPTIMIZE FOR UNKNOWN: IFOBJECTJDlN'dbo.Prod', N'P" nnIS NOT NULL DROP PROC dbo.Protf; GOnCREATE PROC dbo.Prod @Qty AS INTnASnSELECT ProductID, COUNTS) AS NumOrders FROM Sales.SalesOrderDetail WHERE OrderQty >= @Qty GROUP BY ProductID OPTION (OPTIMIZE FOR UNKNOWN); GO
Используйте следующий программный код для тестирования хранимой процедуры: EXEC dbo.Prod @Qty = 40; Я получил такой же план запроса, как показанный на рисунке 2, с оценкой 30%.nnРассмотрим еще один сценарий, в котором используется метод оптимизации для неизвестного.n3. Статистика недоступнаnВозьмем случай, когда гистограмма для фильтруемого столбца отсутствует и вы не позволяете SQL Server создать гистограмму, отключив автоматическое создание статистики на уровне базы данных и не формируя индекс для столбца. Используйте следующий программный код, чтобы организовать такую среду для нашей демонстрации, заменив имя статистики именем, полученным в результате выполнения запроса, приведенного в листинге:n
ALTER DATABASE AdventureWorks2014 SET AUTO_CREATE_STATISTICS OFF;nGOnDROP STATISTICS Sales.SalesOrderDetail. _WA_Sys_00000004_44 CA3770;
Затем выполните код, в котором используется константа в фильтре:n
SELECT ProductID, COUNT П AS NumOrdersnFROM Sales.SalesOrderDetailnWHERE OrderQty >= 40nGROUP BY ProductID;
Выполнив этот запрос ранее, вы получили план, показанный на рисунке 1, с точной оценкой. Но на этот раз у оптимизатора не было гистограммы, поэтому используется метод оптимизации для неизвестного и создается план, показанный на рисунке 2, с оценкой 30%.nnВыполните следующий программный код, чтобы повторно активировать автоматическое создание статистики в базе данных:n
ALTER DATABASE AdventureWorks2014 SET AUTO_CREATE_STATISTICS ON;
Вы можете повторно запустить запрос и убедиться, что вы получаете план, как на рисунке I.nnОценки оптимизации для неизвестных для операторов BETWEEN и LIKEnПри использовании предиката BETWEEN жестко заданные предположения зависят от сценария и применяемой СЕ. В старых СЕ во всех случаях используется оценка 9%. Это демонстрирует следующий запрос. Флаг трассировки 9481 запроса используется, чтобы применить старую СЕ.n
DECLARE ©FromQty AS INT = 40, ©ToQty AS INT = 41;nSELECT ProductID, COUNT (*) AS NumOrdersnFROM Sales.SalesOrderDetailnWHERE OrderQty BETWEEN ©FromQty AND @ToQtynGROUP BY ProductIDnOPTION (QUERYTRACEON 9481);
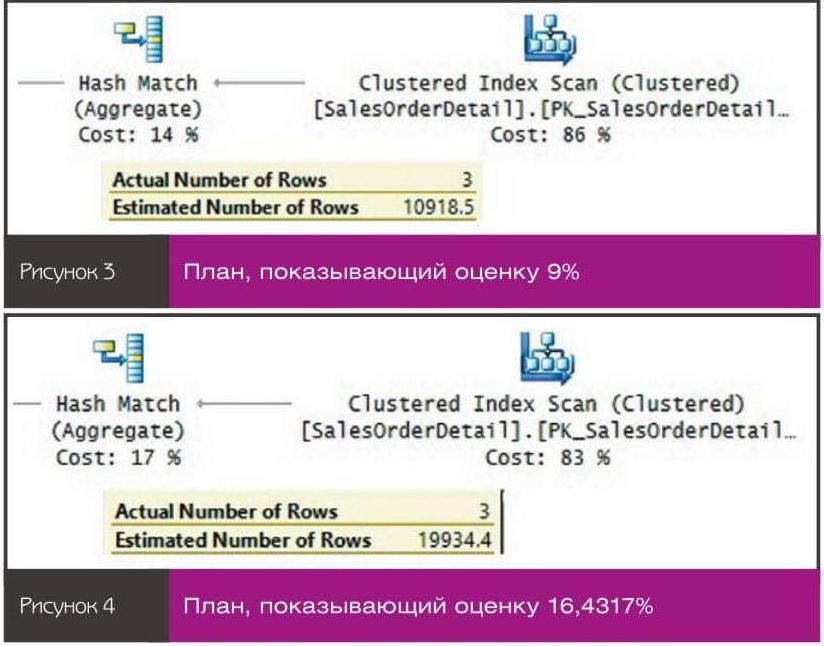
План для этого запроса показан на рисунке 3. Оценка 0,09 * 121317 = 10918,5.nnВ новой СЕ задействованы различные оценки при применении констант и отсутствующей гистограмме и при использовании переменных или параметров с отключенным прослушиванием. В первом случае используется оценка 9%; во втором — оценка 16,4317%. Ниже приводится пример использования констант. Обязательно удалите любую существующую статистику для столбца и отключите автоматическое создание статистики, как показано выше, перед выполнением теста и включите после его завершения.n
ECLARE ©FromQty AS INT = 40, ©ToQty AS INT = 41;nSELECT ProductID, COUNT (*) AS NumOrdersnFROM Sales.SalesOrderDetailnWHERE OrderQty BETWEEN ©FromQty AND ©ToQtynGROUP BY ProductIDnOPTION (QUERYTRACEON 9481);
Я получил такой же план, как на рисунке 3, с оценкой 9%. Ниже приводится пример, демонстрирующий применение переменных (то же поведение, что и при использовании параметров с отключенным прослушиванием):n
DECLARE ©FromQty AS INT = 40, ©ToQty AS INT = 41;nSELECT ProductID, COUNT (*) AS NumOrdersnFROM Sales.SalesOrderDetailnWHERE OrderQty BETWEEN ©FromQty AND ©ToQtynGROUP BY ProductID;
 nn
nn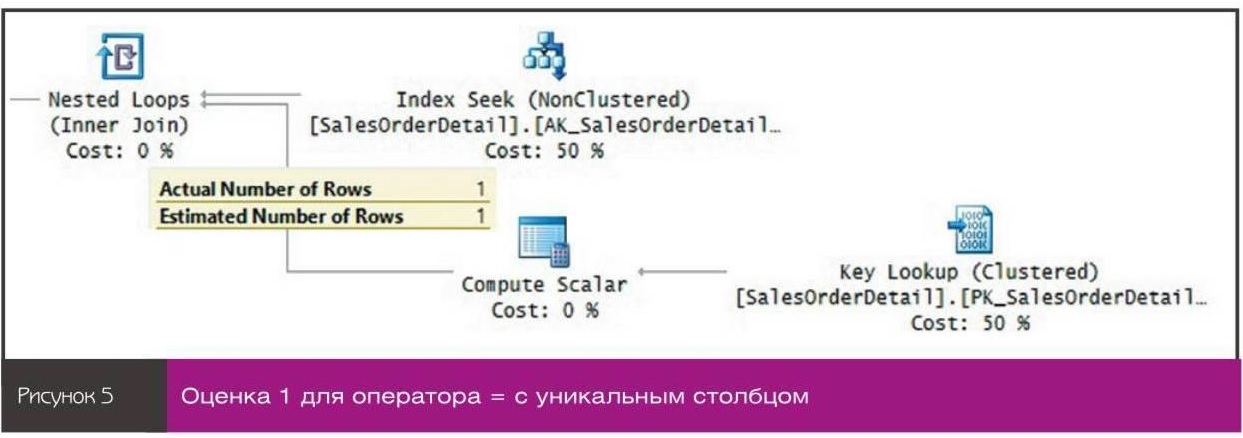 nnЯ получил план, приведенный на рисунке 4, показывающий оценку 16,4317%.nПри использовании предиката LIKE во всех сценариях оптимизации для неизвестного как в старых, так и в новых СЕ применяется оценка 9%. Ниже приведен примере использованием локальных переменных:n
nnЯ получил план, приведенный на рисунке 4, показывающий оценку 16,4317%.nПри использовании предиката LIKE во всех сценариях оптимизации для неизвестного как в старых, так и в новых СЕ применяется оценка 9%. Ниже приведен примере использованием локальных переменных:n
DECLARE ©Carrier AS NVARCHAR (50) = '4911-4030-%';nSELECT ProductID, COUNT AS NumOrders FROM Sales.SalesOrderDetainWHERE CarrierTrackingNumber LIKE ©CarriernGROUP BY ProductID;
Вы увидите ту же оценку 9%, как показано на рисунке 3, хотя в данном случае действительное число строк 12, а ранее было 3nn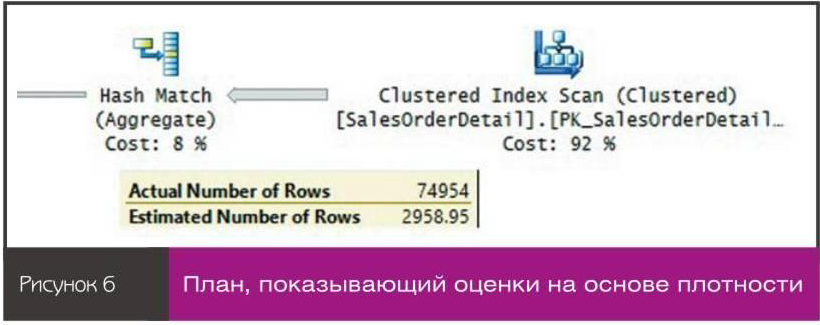 nn
nn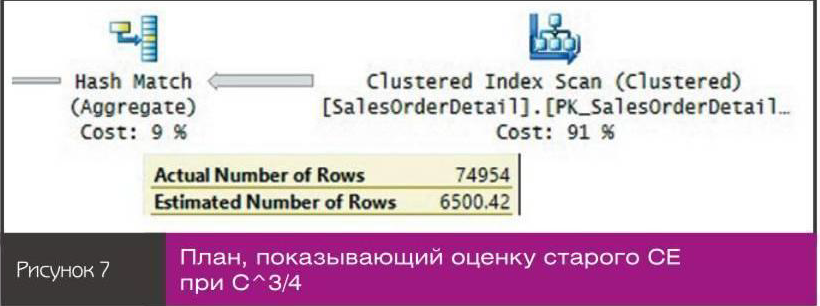 nn
nn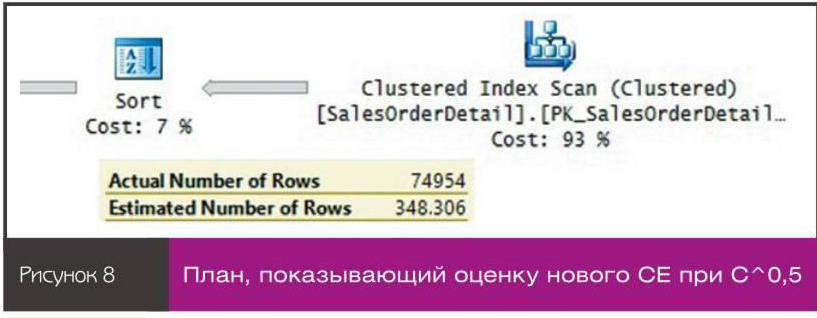 nnОценки оптимизации для неизвестных для оператора =nПри использовании оператора = различают три основных случая:n• уникальный столбец;n• неуникальный столбец и доступная плотность;n• неуникальный столбец и недоступная плотность.nЕсли фильтруемый столбец уникален (для него определены уникальный индекс, ограничение PRIMARY KEY или UNIQUE), то оптимизатору известно, что совпадений не может быть более одного, поэтому оценка равна 1. Ниже приводится запрос, демонстрирующий этот случай:n
nnОценки оптимизации для неизвестных для оператора =nПри использовании оператора = различают три основных случая:n• уникальный столбец;n• неуникальный столбец и доступная плотность;n• неуникальный столбец и недоступная плотность.nЕсли фильтруемый столбец уникален (для него определены уникальный индекс, ограничение PRIMARY KEY или UNIQUE), то оптимизатору известно, что совпадений не может быть более одного, поэтому оценка равна 1. Ниже приводится запрос, демонстрирующий этот случай:n
DECLARE ©rowguid AS UNIQUEIDENTIFIER = 'B207C96D-D9E6-402B-8470-2CC176C42283;nSELECT*nFROM Sales.SalesOrderDetailnWHERE rowguid = ©rowguid
На рисунке 5 показан план для этого запроса с оценкой 1. Если столбец не уникален и оптимизатору доступна информация о плотности (средний процент для отдельного значения), то оценка основывается на плотности. Если не отключено автоматическое создание статистики или для столбца сформирован индекс, то эта информация будет доступна оптимизатору. Чтобы продемонстрировать это, сначала убедитесь, что автоматическое создание статистики включено, выполнив следующий программный код:n
ALTER DATABASE AdventureWorks2014 SET AUTO CREATE STATISTICS ON;
Таблица 2 Оценки метода оптимизации для неизвестного для операторовn
| Оператор | Оценка |
| >, >=, >, <= | 30% |
| BETWEEN до версии SQL Server 2014 | 9% |
| BETWEEN с переменными или параметрами при отключенном прослушивании в SQL Server 2014 | 16,4317% |
| BETWEEN с константами и без статистики | 9% |
| LIKE | 9% |
| = с уникальным столбцом | 1 строка |
| = с неуникальным столбцом при доступной плотности | плотность |
| = с неуникальным столбцом при недоступной плотности до выпуска SQL Server 2014 | С^3/4 (С — оценка таблицы) |
| = с неуникальным столбцом при недоступной плотности в SQL Server 2014 | С^1/2 |
nЗатем выполните следующий запрос:n
DECLARE @Qty AS INT = 1;nSELECT ProductID, COUNT (*) AS NumOrdersnFROM Saies.SalesOrderDetailnWHERE OrderQty = @QtynGROUP BY ProductID;
Помните, что плотность — средний процент для отдельного значения в столбце. Величина рассчитывается как 1/<отдельные_значения>. В столбце OrderQty 41 отдельное значение, поэтому 1/41 = 0,02439. Если применить этот процент к числу строк в таблице, то полученное значение будет очень близким к оценке на рисунке 6. Чтобы увидеть информацию о плотности, используемую SQL Server при выполнении следующего кода (с использованием имени статистики, полученного из запроса, приведенного в листинге):n
DBCC SHOW.STATISTICS (N'Sales.SalesOrderDetail1, N'_WA_Sys_00000004_44 СА3770')nWITH DENSITY.VECTOR; был получен следующий вывод:nAll density Average Length Columnsn0.02439024 2 OrderQty
Очевидно, что метод, основанный на плотности, в целом хорош, когда входные данные, к которым чаще всего направляются запросы, имеют количество элементов, близкое к среднему. Очевидно, что наш случай в последнем примере иной. Величина 1 появляется чаще среднего, поэтому действительное число выше оценки. При использовании неуникального столбца и недоступной плотности в старой и новой СЕ применяютсяnnразличные методы. В старой СЕ используется оценка С^0,75 (степень три четвертых), где С — входное число элементов, а в новой используется оценка С^0,5 (квадратный корень).nЧтобы продемонстрировать это, сначала удалите любую статистику для столбца OrderQty и отключите автоматическое создание статистики, как было показано ранее:n
ALTER DATABASE AdventureWorks2014 SET AUT0_CREATE_STATISTICS OFF;nGOnDROP STATISTICS Saies.SalesOrderDetail. _WA_Sys_00000004_44 CA3770;
Используйте следующий программный код для тестирования старого метода СЕ:n
DECLARE @Qty AS INT=i;nSELECT ProductID, COUNT (*) AS NumOrdersnFROM Saies.SalesOrderDetailnWHERE OrderQty = @QtynGROUP BY ProductIDnOPTION (QUERYTRACE0N 9481);
План для этого запроса показан на рисунке 7.nnОценка 6500,42 — результат вычисления 121317^З/4.nИспользуйте следующий программный код для тестирования нового метода СЕ:n
DECLARE @Qty AS INT = 1;nSELECT ProductID, COUNT AS NumOrdersnFROM Sales.SalesOrderDetai:nWHERE OrderQty = @QtynGROUP BY ProductID;
План для этого запроса показан на рисунке 8.nnОценка 348,306 получена в результате вычисления 121317^0,5.nnПосле завершения тестирования убедитесь, что автоматическое создание статистики вновь включено, выполнив следующий программный код:n
ALTER DATABASE AdventureWorks2014 SET AUTO_CREATE_STATISTICS ON;
Таким образом, метод оптимизации для неизвестного используется оптимизатором SQL Server, чтобы создать оценку СЕ при неизвестных входных данных или недостатке статистики.nnИногда у оптимизатора нет иного выбора, кроме использования этого метода просто из-за нехватки информации. Иногда данный метод применяется принудительно, если метод оптимизации для известного не подходит. Итак, метод оптимизации для неизвестного применяется в следующих случаях:n1. Использование переменных (кроме случаев использования RECOMPILE на уровне инструкций).n2. Использование параметров с указанием OPTIMIZE FOR UNKNOWN или OPTIMIZE FOR (©parameter UNKNOWN) или флагом трассировки 4136 (всегда при использовании хранимой процедуры, скомпилированной в собственном коде).n3. Статистика недоступна.nВ таблице 2 приведена сводка оценок оптимизации для неизвестного, используемых для различных групп операторов.