Часто бывает, что когда мы спрашиваем клиента, какое время простоя допустимо для его сервисов, он очень настойчиво объясняет, что его системы должны быть доступны 24 на 7. Однако он достаточно быстро меняет свое мнение, узнав, каких денег это будет стоить.nnДавайте разберемся, как быстро можно получить рабочую систему после сбоя и что для этого нужно.nnИтак. Случай первый. Простой нескольких десятков секунд системы ведет к большим потерям (в первую очередь речь здесь идет о прибыли, однако возможны и другие варианты). В таком случае для Ваших систем оправдано использование кластеров непрерывной доступности (Continuous Availability, CA). Под кластером непрерывной доступности мы понимаем набор узлов системы, при отказе одного из которых, Ваши сервисы остаются полностью доступны с момента аварии. Время простоя вышедшего из строя узла имеет значение лишь с той точки зрения, что система теперь находится в аварийном режиме и является более уязвимой в случае выхода из строя оставшихся узлов.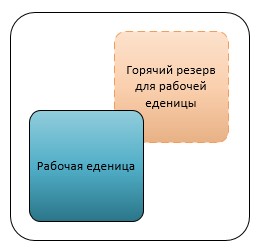 Такие решения могут строиться на аппаратных кластерах или на программных решениях. Созданием аппаратных платформ занимаются такие компании как, Stratus, IBM. В качестве примера программной реализации можно привести VMWare Fault Tolerance. По сути, для каждого уязвимого узла или собственно бизнес-сервиса в горячем резерве держится копия которая становится рабочей при выявлении факта отказа основной рабочей единицы. Каждое решение имеет свои особенности реализации и ограничения. Цена одного узла для кластера непрерывной доступности будет приблизительно стартовать от нескольких тысяч долларов, а стоимость комплексного решения будет зависеть от требуемой Вами архитектуры решения.nnСлучай второй. Возможен простой системы до нескольких минут. В таком случае можно ограничиться использованием кластеров высокой доступности (High Availability, HA). Отличие их от CA заключается в том, что Ваши сервисы будут недоступны некоторое непродолжительное время, пока системы запустятся на новом узле. Тут решений значительно больше. И зачастую реализованы они на уровне виртуализации. Наиболее известные из них:
Такие решения могут строиться на аппаратных кластерах или на программных решениях. Созданием аппаратных платформ занимаются такие компании как, Stratus, IBM. В качестве примера программной реализации можно привести VMWare Fault Tolerance. По сути, для каждого уязвимого узла или собственно бизнес-сервиса в горячем резерве держится копия которая становится рабочей при выявлении факта отказа основной рабочей единицы. Каждое решение имеет свои особенности реализации и ограничения. Цена одного узла для кластера непрерывной доступности будет приблизительно стартовать от нескольких тысяч долларов, а стоимость комплексного решения будет зависеть от требуемой Вами архитектуры решения.nnСлучай второй. Возможен простой системы до нескольких минут. В таком случае можно ограничиться использованием кластеров высокой доступности (High Availability, HA). Отличие их от CA заключается в том, что Ваши сервисы будут недоступны некоторое непродолжительное время, пока системы запустятся на новом узле. Тут решений значительно больше. И зачастую реализованы они на уровне виртуализации. Наиболее известные из них: n
n
- VMware vSphere;
- Windows Server Failover Clustering в связке с серверной ролью “Hyper-V”;
- Red Hat Enterprise Virtualization;
- XenServer;
- Proxmox VE;
- oVirt;
- другие
Для реализации вам нужно несколько (желательно) однотипных серверов. В примитивном варианте это будет работать так: на обоих серверах развернута система виртуализации и Ваши бизнес сервисы запущены внутри виртуальных машин. В случае отказа одного из виртуальных серверов, все находившиеся на нем виртуальные машины запускаются на втором сервере. Не забывайте о том, что для надежности должны быть задублированы все узлы кластера, в частности не только сервера, но и хранилища, и линии связи. Какое решение выбрать – зависит от Ваших требований и возможностей.nnСлучай третий. Вы допускаете перебои в работе Ваших сервисов до нескольких часов.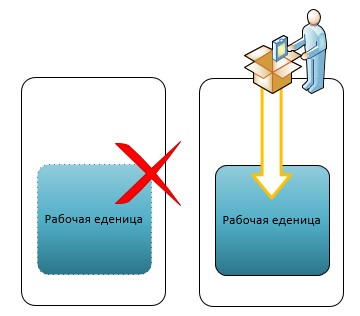 Тогда в случае аварии может оказаться вполне достаточно просто развернуть Ваши системы из резервной копии. Однако, чтобы простой бизнес систем действительно занимал не более нескольких часов, к обслуживанию систем нужно подойти очень ответственно.n
Тогда в случае аварии может оказаться вполне достаточно просто развернуть Ваши системы из резервной копии. Однако, чтобы простой бизнес систем действительно занимал не более нескольких часов, к обслуживанию систем нужно подойти очень ответственно.n
- Во первых – резервные копии должны быть, и они должны быть рабочими. Следовательно, нужно периодически выполнять резервное копирование и проверку созданных бекапов.
- Во вторых, нужно иметь планы восстановления из резервной копии, поскольку даже самый опытный системный администратор, знающий досконально именно Вашу систему, может в критической ситуации (проверено опытным путем), забыть выполнить ту или иную настройку.
- В третьих, чтобы сбои не случались часто, нужно внимательно следить за работой системы и предотвращать проблемы до их появления.
В первую очередь это касается безопасности и потребления ресурсов системы. Своевременно и грамотно обновляйте систему, наблюдайте за потреблением ресурсов и своевременно наращивайте мощности, на основе имеющихся данных старайтесь предугадать нагрузки в проблемные промежутки времени (например, в случае создания отчетности в конце месяца, или во время новогодних распродаж). Не допускайте непроверенных изменений. Используйте технологии, упрощающие перенос данных и снижающие зависимость ПО от аппаратной составляющей.nnСтоит заметить, что советы, которые мы привели в описании третьего случая, рекомендуется выполнять для любых систем. Потому что никогда нет 100% гарантии, что все пойдет, как запланировано. И «секретный план Б» нередко спасал положение даже при наличии катастрофоустойчивых систем.n
Если у Вас есть вопросы по планированию или реализации любых видов отказоустойчивых систем или правильной организации мониторинга и резервного копирования Ваших сервисов – наши специалисты всегда готовы прийти к Вам на помощь. Подробнее office@itfb.com.ua