Сравниваем решения для обеспечения бесперебойной работы критически важных бизнес-приложенийnnСегодня от любой системы или службы требуется постоянная доступность. Говорим мы об информационных сервисах предприятия, управлении производственными циклами, работе систем безопасности, реагировании аварийных служб, выполнении банковских операций — затронут буквально каждый момент повседневной жизни.nnИнформационные инфраструктуры, обеспечивающие функционирование многих систем в мире, в настоящее время виртуализируются. Большие и малые предприятия внедряют виртуализацию, чтобы использовать такие ее преимущества над традиционными физическими платформами, как динамичность, эффективность и масштабируемость. По мере того, как все большее число критически важных приложений виртуализируется, главным приоритетом становится обеспечение их постоянной работоспособности.nnСтоимость простоя компании в связи с отказом информационных систем увеличивается с каждым годом и для крупных предприятий уже превысила ошеломляющие $650 000 в час. Непредвиденная остановка ключевых приложений, приводящая к потере данных или пропуску операций, становится просто неприемлемой. В ситуации, когда на одном физическом сервере выполняется несколько виртуальных машин, один аппаратный сбой может приводить к масштабным негативным последствиям для бизнеса.nnОдним из распространенных подходов для минимизации времени простоя является создание серверного кластера с механизмом аварийного переключения, который перезапускает виртуальную машину на другом узле в случае аппаратного сбоя или ошибки операционной системы. В таком случае процесс восстановления не только занимает много времени, но и подразумевает несение определенного ущерба. Но в идеальном случае, система, исполняющая важное для предприятия виртуализированное приложение, должна исключить перерыв в его работе даже в условиях отказа оборудования.nnВ этой статье сравниваются два программных продукта для обеспечения доступности приложений: VMware vSphere HA или FT и Stratus everRun.n
Внедрение решения: сложность или простота
Создание среды с высоким уровнем доступности, основанном на кластеризации, сложное и затратное дело. В среде VMware для включения системы аварийного переключения вам потребуются кластер из двух узлов, сеть хранения данных и дополнительная сеть VMware vMotion для переноса виртуальной машины с одного узла на другой. Необходимо настроить целый ряд параметров, чтобы определить, как кластер HA или FT будет вести себя в случае сбоя и обеспечить наличие ресурсов для перехода виртуальной машины с одного узла на другой.nnСистема Stratus everRun строится только на двух x86 серверах, работающих под управлением Centos Linux. Также используются гипервизор с открытым исходным кодом KVM и специальное ПО Availability Extensions, обеспечивающее перенаправление ввода-вывода и синхронизацию узлов системы (см. рис. 1).nn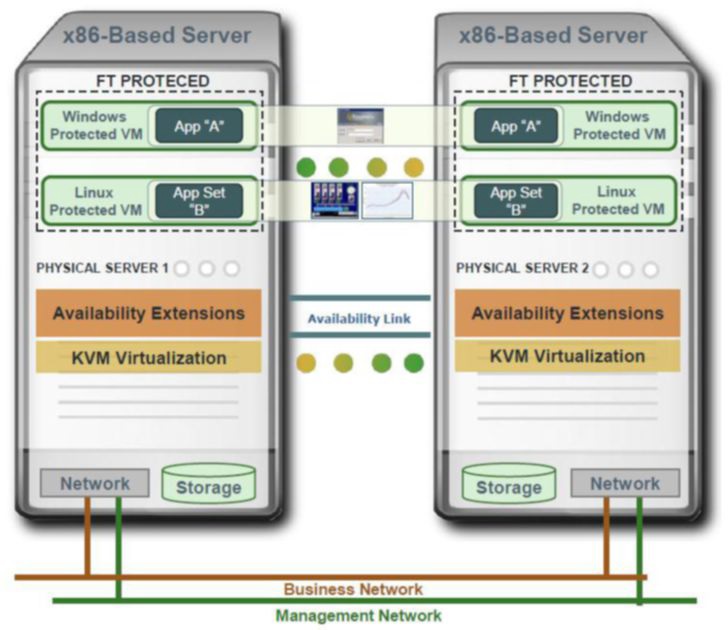 nn
nn
ПО everRun устанавливается на оба сервера в несколько шагов, основная настройка происходит автоматически. Виртуальные машины создаются и управляются через встроенный web-интерфейс everRun Availability Console. Установка гостевой ОС и приложений выполняется один раз, после чего everRun создаст ее дубликат и начнет непрерывно зер-калировать диски между физическими узлами, операции ввода-вывода, состояние оперативной памяти и распределять нагрузку для оптимального использования вычислительных ресурсов.nnStratus everRun предлагает выбор двух уровней доступности — отказоустойчивость (fault tolerance, FT) и высокая доступность (high availability, HA).nnВ случае выбора режима FT, состояние виртуальной машины на обоих физических узлах будет полностью идентичным. Режим FT характеризуется полным отсутствием единой точки отказа. Состояние подсистемы хранения зеркалиро-вано между узлами, и в использовании внешних запоминающих устройства нет необходимости.nnПри выборе уровня защиты HA, благодаря избыточности на уровне компонентов, система выдерживает сетевые сбои и отказы системы хранения без простоя. При отказе физического узла целиком, виртуальная машина автоматически восстанавливается на другом узле. Как и в FT, нет необходимости в использовании SAN или внешних запоминающих устройства.nnИ в случае HA, и в случае FT обеспечивается активное наблюдение за состоянием аппаратного обеспечения обоих серверов, автоматическая обработка ошибок и восстановление.n
Общая оценка расходов
Кластеру vSphere HA/FT требуется выделенная консоль управления, высокодоступная сетевая инфраструктура и внешняя система хранения данных. Stratus everRun не требует каких-либо дополнительных сетей или систем хранения. К тому же, установка everRun значительно проще, а, следовательно, и менее дорогостоящая по сравнению с vSphere.nnУправление и поддержка также являются важными факторами стоимости. Кластерам часто требуется ручное управление, что вызывает затраты на административный персонал. Любые изменения в программном или аппаратном обеспечении в используемом кластере должны аккуратно проверяться перед внедрением.nnАдминистрирование everRun минимально. Автоматический внутренний механизм осуществляет мониторинг за приложениями и устройствами. Обнаружение проблемы вызывает выполнение встроенного скрипта для ее устранения, перезапуск приложения при необходимости и немедленное оповещение через SNMP.n
Обработка отказов и ограничения
vSphere HA и everRun предлагают два разных подхода: кластеры vSphere HA полагаются на перезапуск приложения после сбоя сервера, а everRun обеспечивает предотвращение простоев. Из-за этих различий есть факторы, которые следует учитывать при оценке двух решений.nnvSphere HA сокращает время простоя за счет автоматического перезапуска виртуальных машин, но не защищает сервер от снижения производительности. При этом данные, не записанные на диск, теряются при отключении электропитания. Повторный запуск приложения зависит от его типа и не может быть мгновенным. Так, среда SAP может находиться в автономном режиме в течение долгого времени после перезапуска (источник: SAP Saber — Carving SAP into separate landscapes for company split. Van Vi and Rick Jones.):n
> ABAP Central/Dialog Instances - ~ 4-5 минут для перезагрузки ОС и запуска SAP.nn> Java Central/Dialog Instances — 15-17 минут для перезагрузки ОС и запуска SAP.nn> DB Instance — 4-5 минут для перезагрузки ОС и восстановления SQL Server.nn> Web-Dispatcher Instance - ~ 3-4 минуты.
В Stratus everRun приложение находится одновременно на двух виртуальных машинах. Если одна выходит из строя, приложение продолжает работать на другой без перерывов и потери данных. При сбое компонента на сервере приложение использует дубликат компонента из второго сервера.nnВ настоящее время VMware FT поддерживает до четырех виртуальных процессоров на одну виртуальную машину и максимум четыре защищенные ВМ на одном физическом узле с общим количеством vCPU не более 8. А многие критичные приложения чувствительны к производительности и требуют интенсивной многоядерной симметричной многопроцессорной обработки. Например, Microsoft рекомендует от 4 до 12 процессорных ядер для Exchange Server и от 4 до 8 ядер для SharePoint и SQL Server. Oracle рекомендует от 6 до 12 ядер.nnStratus everRun поддерживает до 8 vCPU на защищенной виртуальной машине и не имеет каких-то дополнительных ограничений, что делает его более удобным для пользователей и экономически эффективным решением.nnИсточник: Журнал Системный администратор апрель 2016n
■ • ■
nn
Наша компания выполняет роль системного интегратора и предоставляет услуги по настройки и поддержке систем виртуализации, подробсности через раздел Контакты.