Содержание:
- Введение
- Требования клиентов
- Решение требований и уровни внедрения мониторинга
- Первый уровень – простой
- Второй уровень – логи
- Третий уровень – точный многозвенный
- Метрики backend
- Метрики баз данных
- Про workflow работы с инцидентами
- Severity алертов
- Работа с алертами и классификация
Любой IT проект должен выполнять возложенные на него бизнесс-задачи. От его работоспособности напрямую зависит многое – это и прибыль владельца, и удовлетворенность пользователей. В конце концов, сегодня любая сфера использует Интернет. На стадии разработки и запуска в продакш невозможно гарантировать стабильную работу сайта в будущем. Владелец сайта рано или поздно приходит к тому, что ему нужна система мониторинга. При этом не всегда понятно, какие функции необходимо возложить на систему мониторинга. У компании okmeter есть общий многоуровневый алгоритм мониторинга проекта. Программное обеспечение okmeter делает упор на детализацию, преднастроенные триггеры и автоконфигурацию.
Требования клиентов
Какие проблемы хочет решить клиент через мониторинг? Какие требования?
- В случае неполадок в работе, оповещение от мониторинга (а не по претензиям клиентов).
- Минимизация времени поиска причины проблем.
- Минимизация времени исправления.
Второй и третий пункт вместе – время downtime дальше по тексту.
Решение требований и уровни внедрения мониторинга.
Первый уровень, подходящий для простого сайта – установить софт pingdom или аналогичный.
Основный недостаток – такая система может пропускать проблемы. Но для простого сайта это может быть не критичным.
Преимущества: легко внедрить; обычно есть много встроенных сервисов; дешево/бесплатно.
Недостатки: большая погрешность; низкое покрытие сайта метриками; пропуск ошибок.
Второй уровень – обработка логов. Для этого необходимо установить клиент на frontend. Установленный okmeter не требует конфигурации, так как он видит процесс nginx, читает config файл и знает все логи. Для работы обязательно должны быть включены тайминги в логе, так как в стандартном nginx их нет. Нужно добавить как минимум: $request_time, $upstream_response_time, $upstream_cache_status.
Далее пять примеров снятия детализированных данных по двум метрикам с логов и их визуализации.
Общий шаблон метрики nginx.requests.rate выглядит так:
{name="nginx.requests.rate" file = "/log_path.log" plugin="nginx" source_hostname = "front1"
method = "X" status = "YYY" cache_status = "zzz" url = "/xxx"}
Таким образом, метрика может быть детализирована по host, по логу, по http методу, по статусу, по статусу cash и по url. URL здесь обрабатывается дополнительно: убираем аргументы, идентификаторы, группируем по количеству запросов.
sum_by (source_hostname, metric (name = "nginx.requests.rate"))
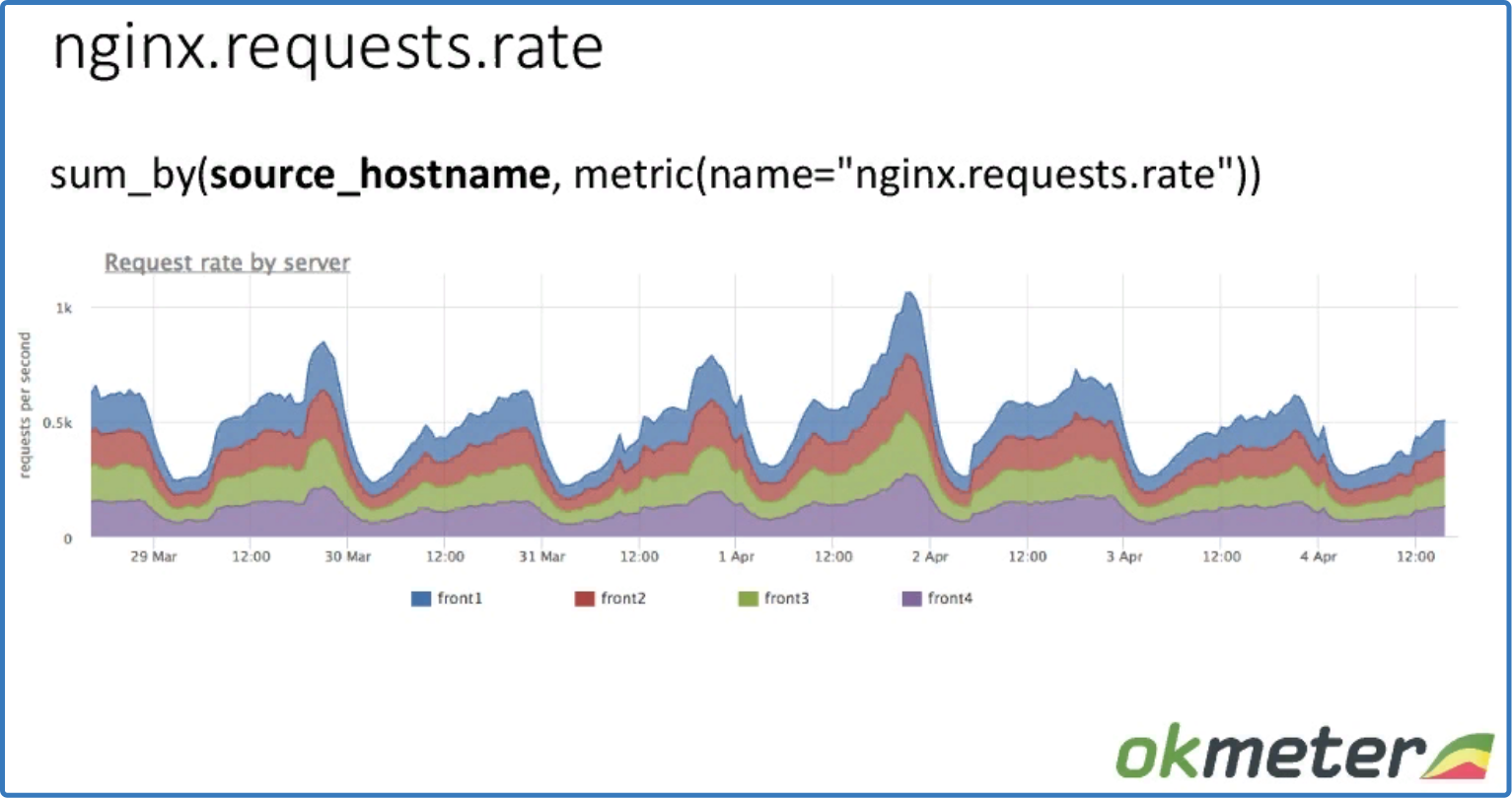
Видим, как распределены request по машинам, суммарный rps и как балансируется.
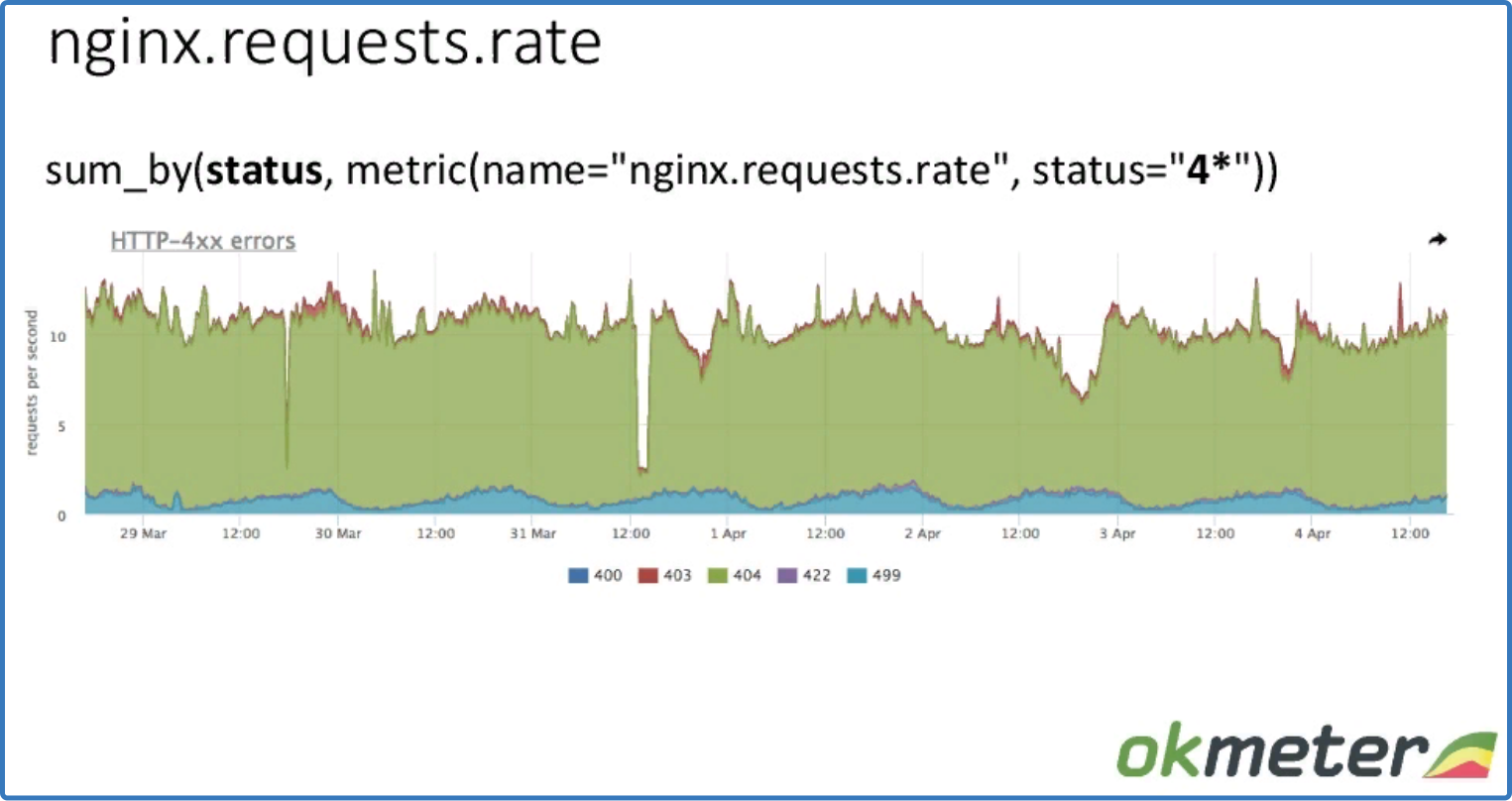
sum_by (status, metric (name = "nginx.requests.rate", status = "4*"))
детализация по статусу
Видим суммарный rps по статусу.
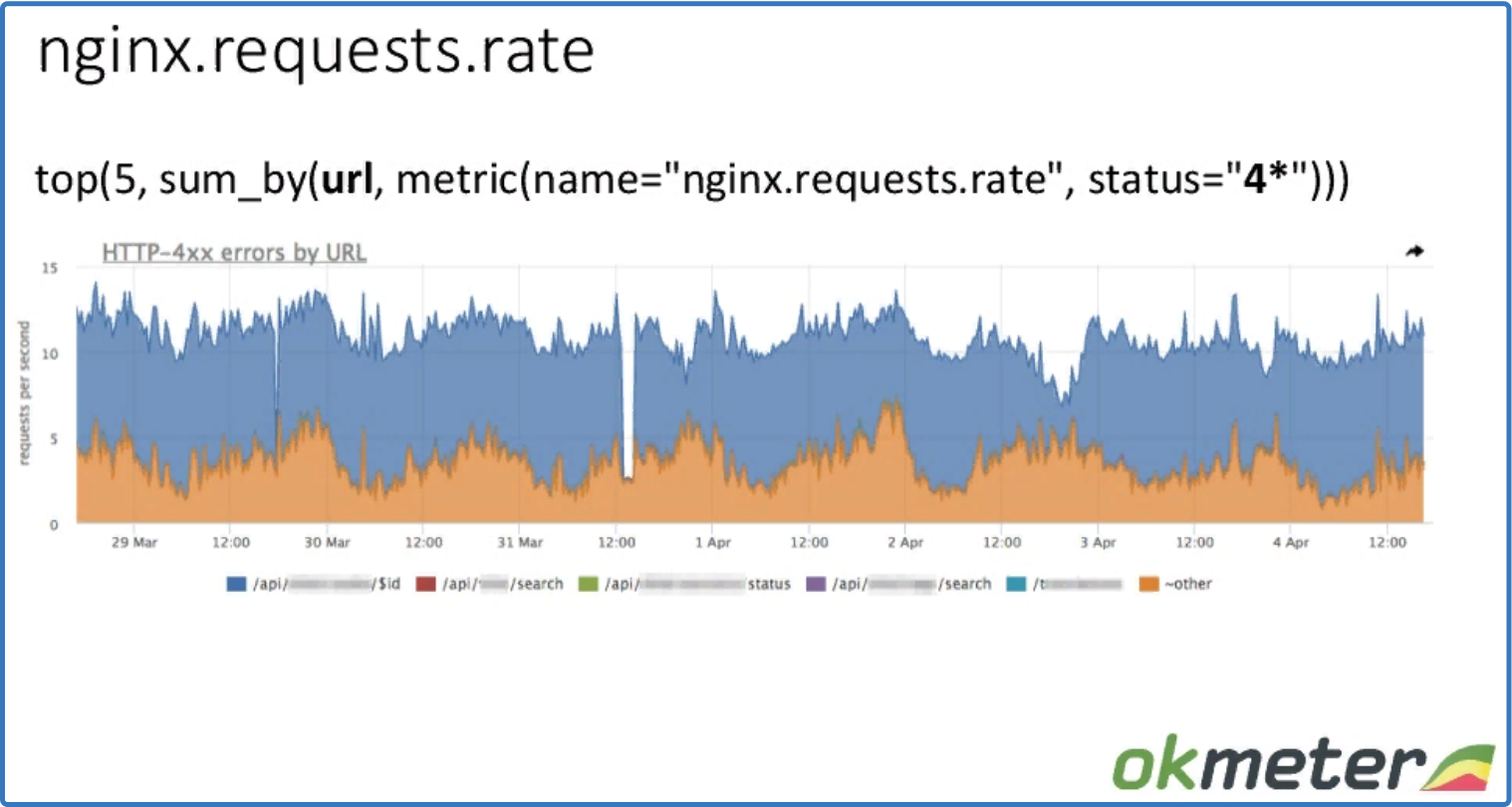
top (5, sum_by (url, metric (name = "nginx.requests.rate", status = "4*")))
детализация по статусу с разбивкой по URL
Та же самая метрика, но отвечает на разные вопросы. Видим rps ошибок по URL.
Общий шаблон метрики nginx.response_time.histogram для построения гистограмм.
{name = "nginx.response_time.histogram" file = "/log_path.log" plugin = "nginx"
source_hostname = "front1" method = "X" cache_status = "zzz" url = "/xxx" level = "ll"}
Фактически та же метрика, но дополнительно есть level по времени, и он определяет, в какой bucket попадает запрос.
sum_by (level, metric (name = "nginx.response_time.histogram"))
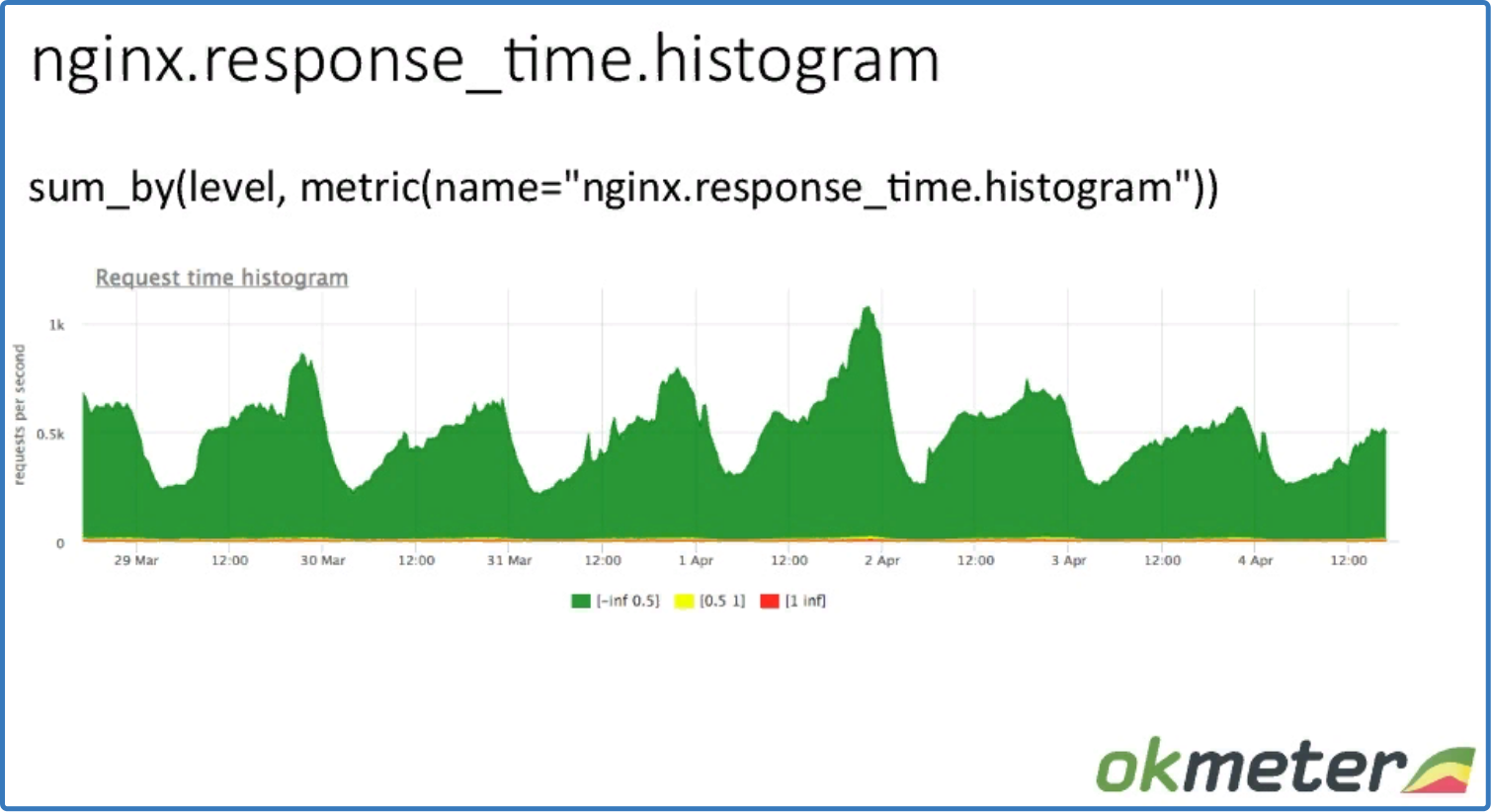
Здесь данные rps суммированы по всем серверам.
sum_by (level, metric (name = "nginx.response_time.histogram", url = "/api*"))
детализация по URL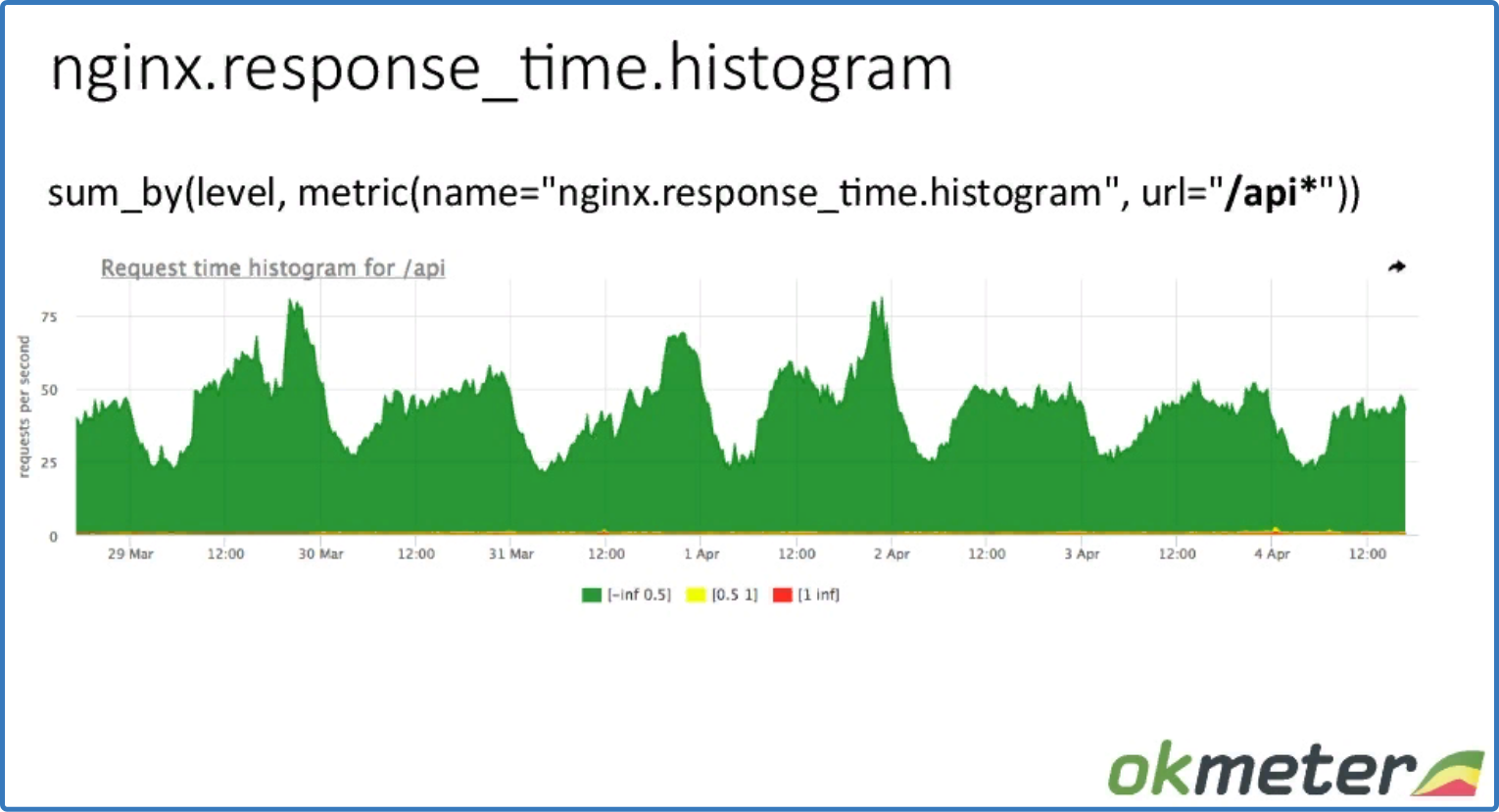
Видим данные rps по определенному URL по маске, суммированные по серверам.
В чем разница между $request_time и $upstream_response_time в nginx?
$request_time показывает всё время от начала до передачи последнего байта в socket клиента. С его помощью можно выявить проблемы связанности клиента с вашим сервером. Будет видно время бана, если настроен limit_req+burst. Но не будет понятно, откуда проблема: от хостера или от сервера.
$upstream_response_time показывает реальные проблемы, связанные с backend, или ложные, если ioloop nginx заблокировался.
Таким образом, нужно снимать обе метрики, чтобы узнать причину проблемы.
Преимущества:
- возможность обработать все запросы реальных пользователей
- точная информация об ошибках, таймингах.
Недостатки:
- затраты ресурсов на парсинг
- времена считается по версии сервера
- сложно определить причину проблем, если нет запросов совсем (неполадки с каналом, доменом и др.)
Третий уровень – углубленный мониторинг многозвенной архитектуры с целью минимизации downtime. Многозвенная архитектура характерна даже для простого интернет-магазина. Frontend, битрикс, база данных – минимальные составляющие, и это уже много звеньев. Чтобы контролировать такую систему, нужно понимать взаимосвязи:
- client → frontend
- frontend → backend
- backend → backend
- backend → DB
- DB→ backend
- OS → потребление ресурсов всеми приложениями и базой данных (DB).
Так как все компоненты связаны между собой через сеть, и она находится под нагрузкой, необходимо снимать метрики со всех зависимостей. Почему нельзя ограничиться одним слоем? Потому что, от любого уровня может поступать ложная информация. И, получая информацию из разных источников, можно выяснить реальную причину проблемы. Для этого нужно анализировать аномалии и несостыковки.
Метрики backend:
Стандартный агент okmeter снимает потребление ресурсов всеми процессами. Основные метрики:
- Метрики ресурсов: cpu, mem, disk io, fd;
- Метрики ограниченных ресурсов: open files limit, tcp ack backlog limit и др.;
- Метрики runtime платформы: gc, memory pools, workers;
- Метрики скриптов.
sum_by (source_hostname, metric (name = «process.cpu.*», process = «/usr/bin/python»))
данные по нагрузке на CPU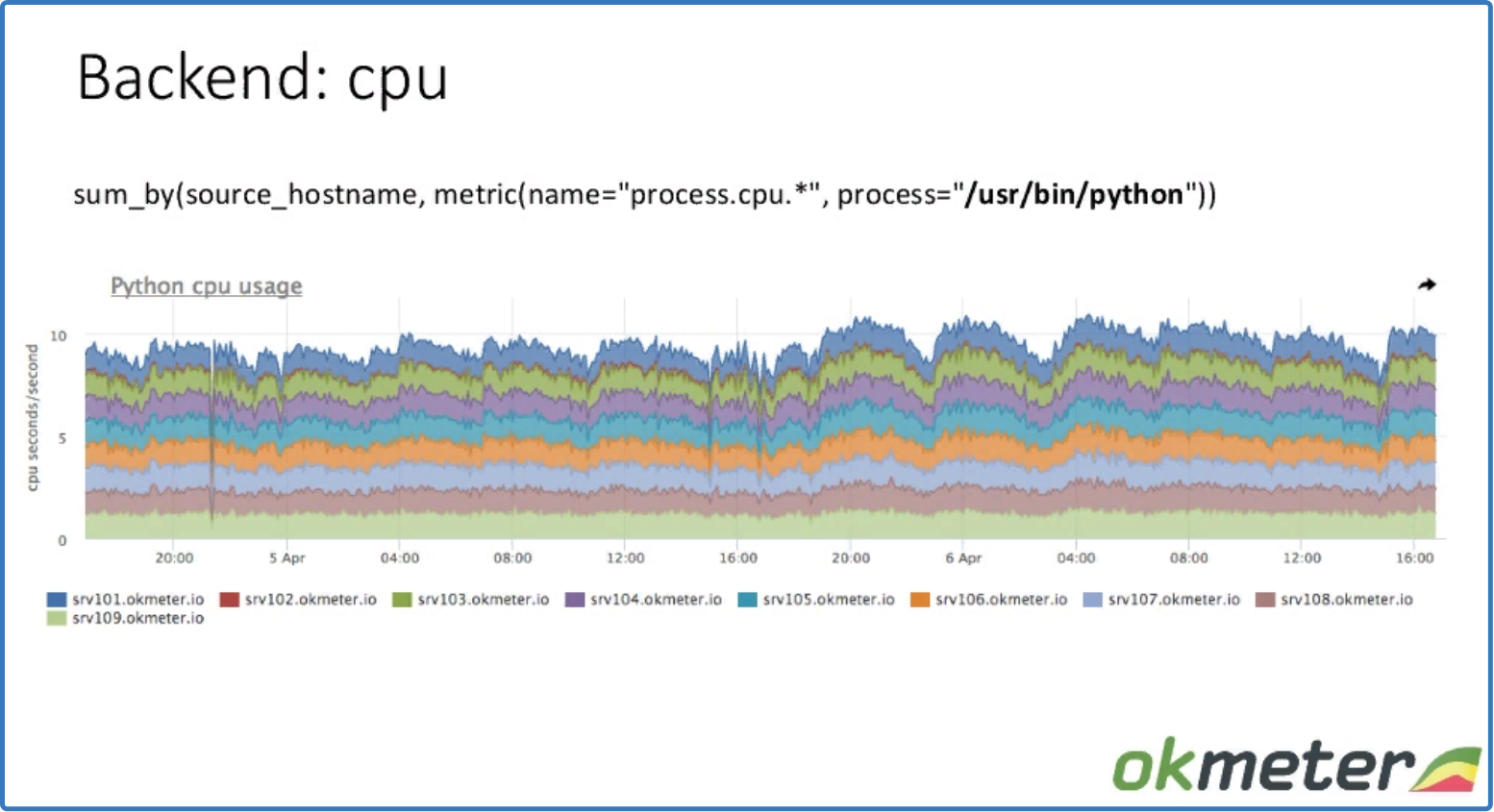
Видим сколько процесс (/usr/bin/python) потребляет CPU на определенных машинах по маске (process.cpu.*). Метрики снимаются со всего кластера, чтобы выявить разбалансировку.
sum_by (source_hostname, metric (name = "process.mem.rss", process = "/usr/bin/python"))
данные использования памяти суммированы по хостам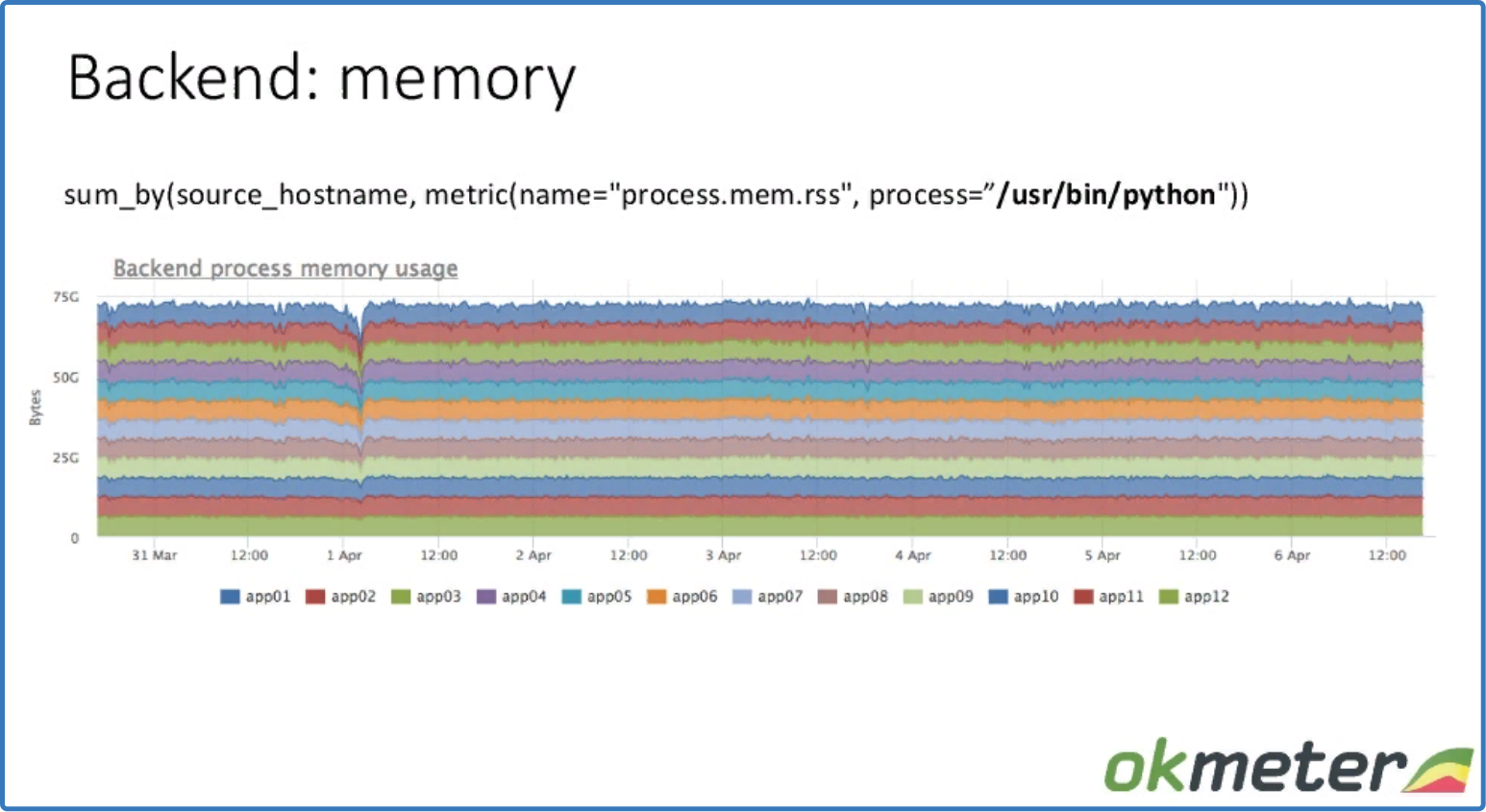
Видно, что нигде нет утечки, и память используется равномерно.
Для снятия метрик runtime платформы у okmeter есть агент, написанный на Go, и он присылаем метрики своего runtime. Это, в частности, количество секунд потраченных garbage collector Go в секунду. Эта величина будет разной у разных машин. Другая метрика runtime – количество аллоцируемой памяти в единицу времени. Дает информации о том, какую память платформы аллоцируют на каждой машине.
counter_rate (metric (name = "okagent.gc.time", source_hostname = ["srv10*", "es10*"]))
данные по работе garbage collector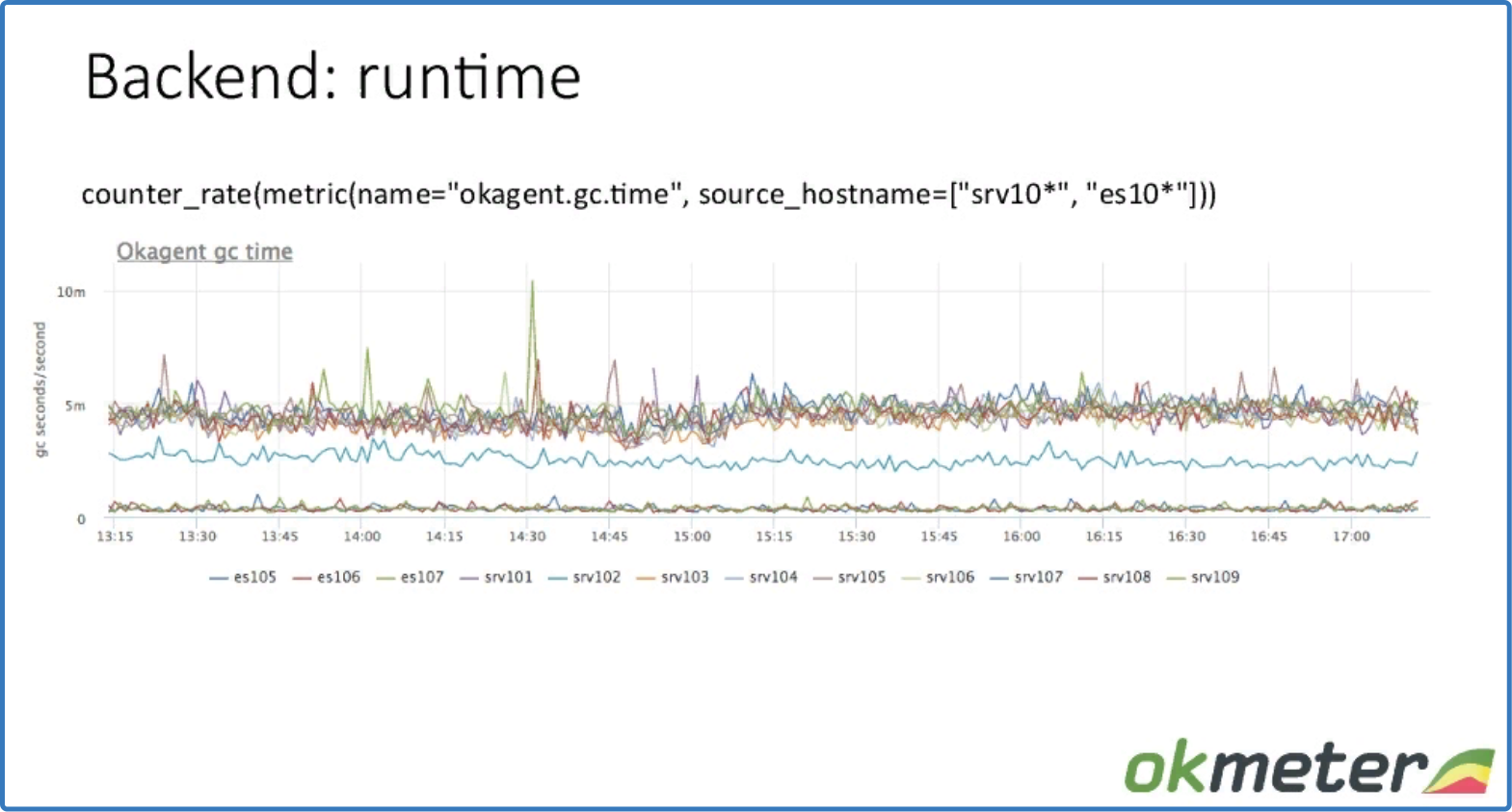
Видим, количество секунд потраченных garbage collector Go в секунду на разных машинах
counter_rate (metric (name = "okagent.memstats.total_alloc", source_hostname = ["srv10*", "es10*"]))
данные по аллоцированию памяти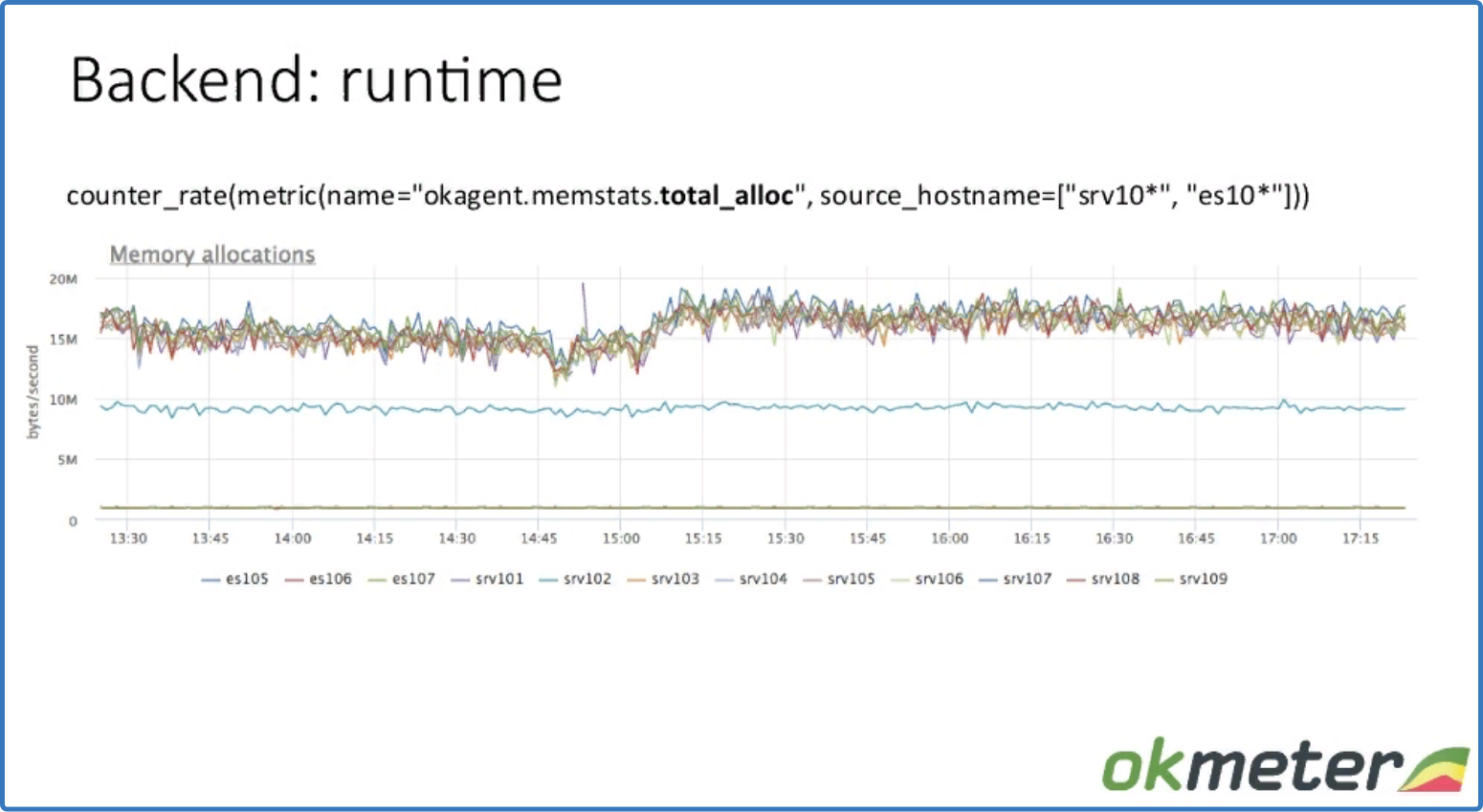
Для инструментирования нужно определенное расширение. Например, для php – это pinba. Показывает %CPU, память и трафик, потраченные на определенный скрипт.
top (5, sum_by (script, metric (name = "pinba.cpu.time")))
топ 5 скриптов по потреблению %CPU на примере использования pinba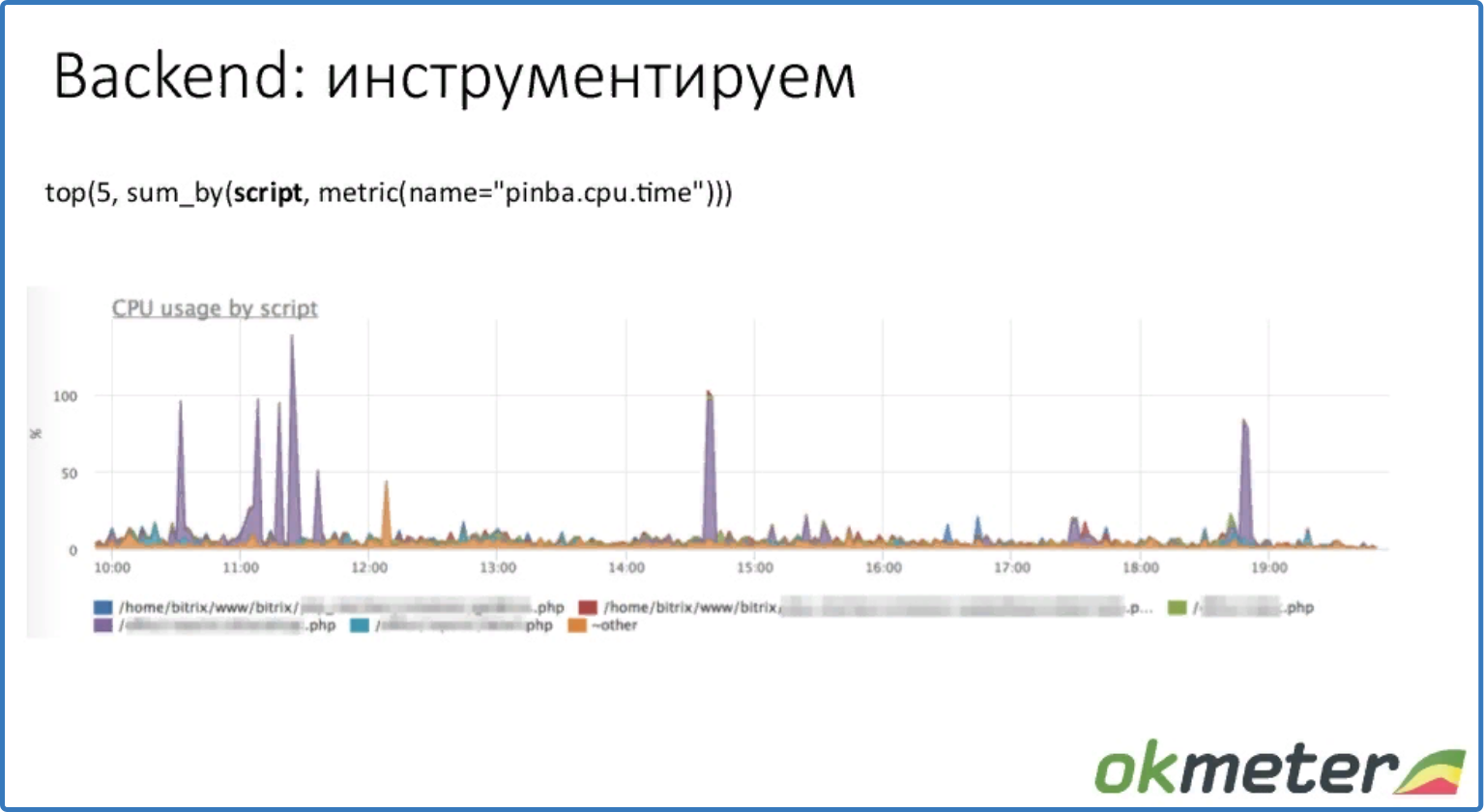
Видим, что есть пики у определенного скрипта. Проблема выявлена, и можно разбираться, почему этот файл потребляется высокий %CPU.
top (5, sum_by (script, metric (name = "pinba.traffic.rate")))
топ 5 скриптов по потреблению памяти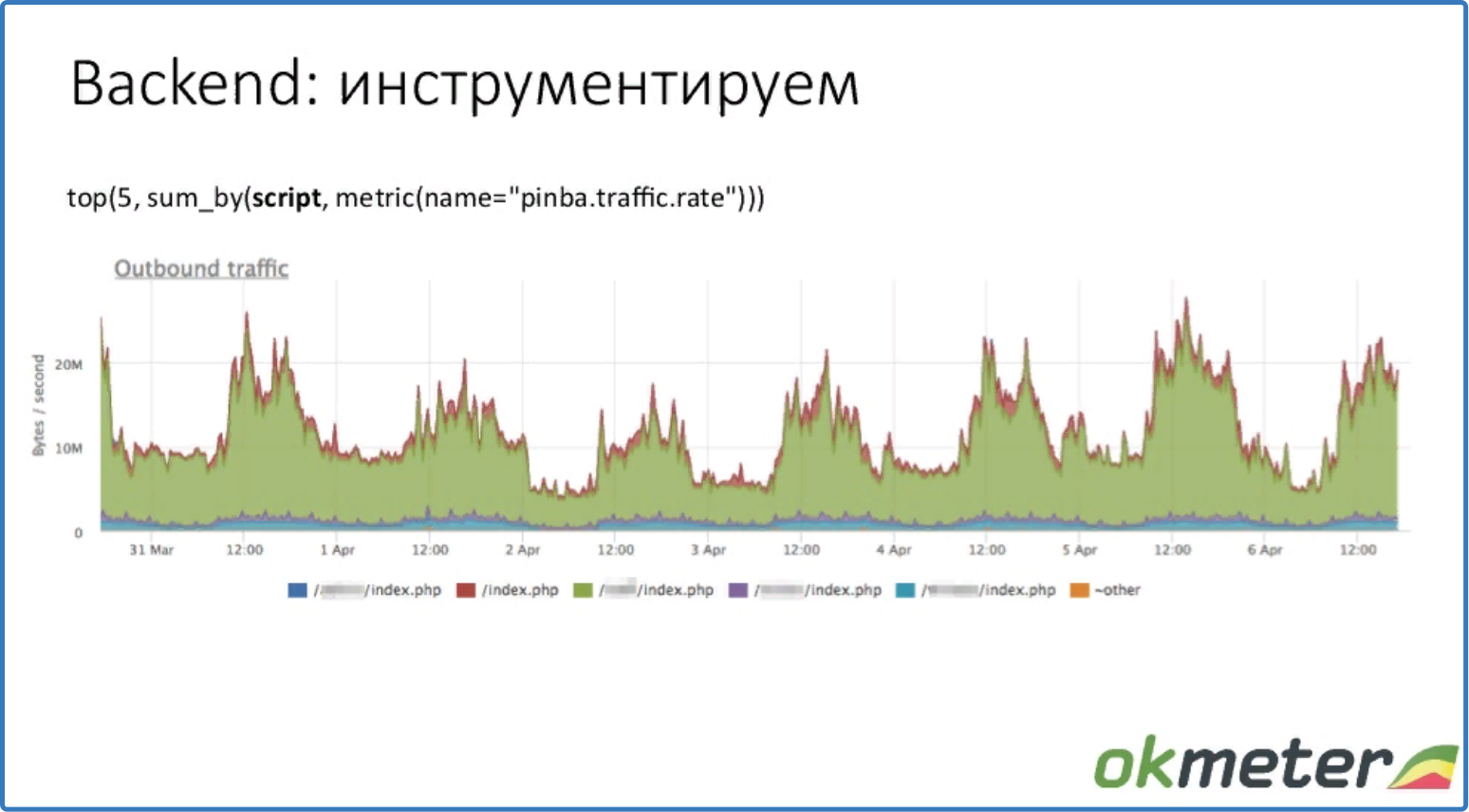
Видим топ 5 скриптов по трафику.
top (5, sum_by (stage, metric (name = "gokserver.handler_stages.sum", handler = "/metric/query")))
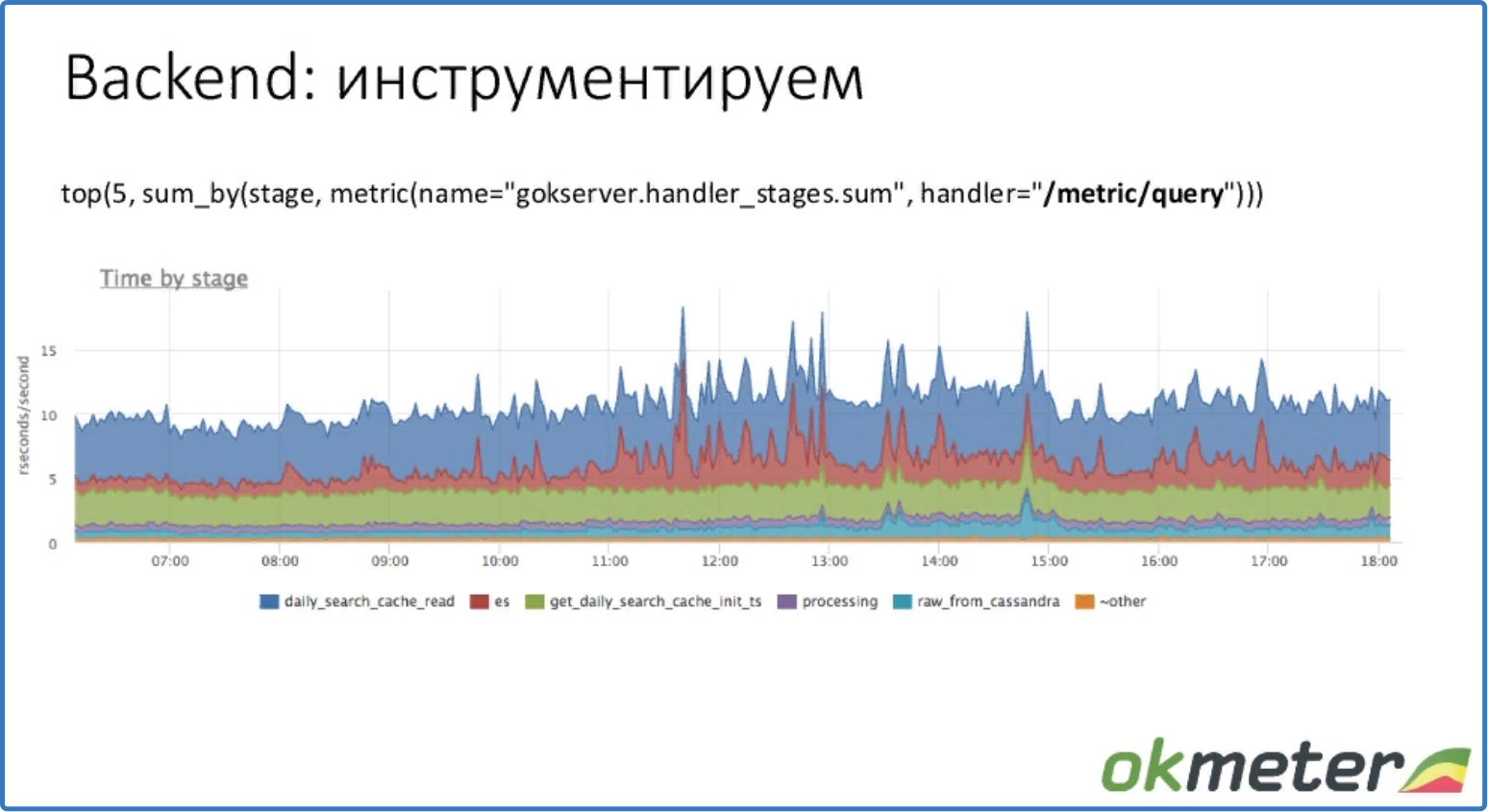
Видим, какие стадии сколько ресурсов использовали. Стадии здесь – фактически куски кода. Handler – внутренний обработчик okmeter.
Application performance monitoring. Развивать мониторинг backend глубже возможно. Например, можно делать tracing конкретного запроса пользователя, и получать информацию о таймингах отдельного request. В okmeter такой мониторинг не входит.
Про базы данных.
Основные метрики:
- Метрики потребления ресурсов: cpu, mem, disk io, fd.
- Метрики деградации ресурсов: open files limit, tcp ack backlog limit и др.
Хорошо, если данные детализированы по запросам. Тогда при проблемах сразу виден запрос, из-за которого база стала больше потреблять ресурсов. При анализе важно учитывать latency базы данных.
sum_by (process, metric (name = "process.disk.ops.write", process = "/usr/libexec/mysqld"))
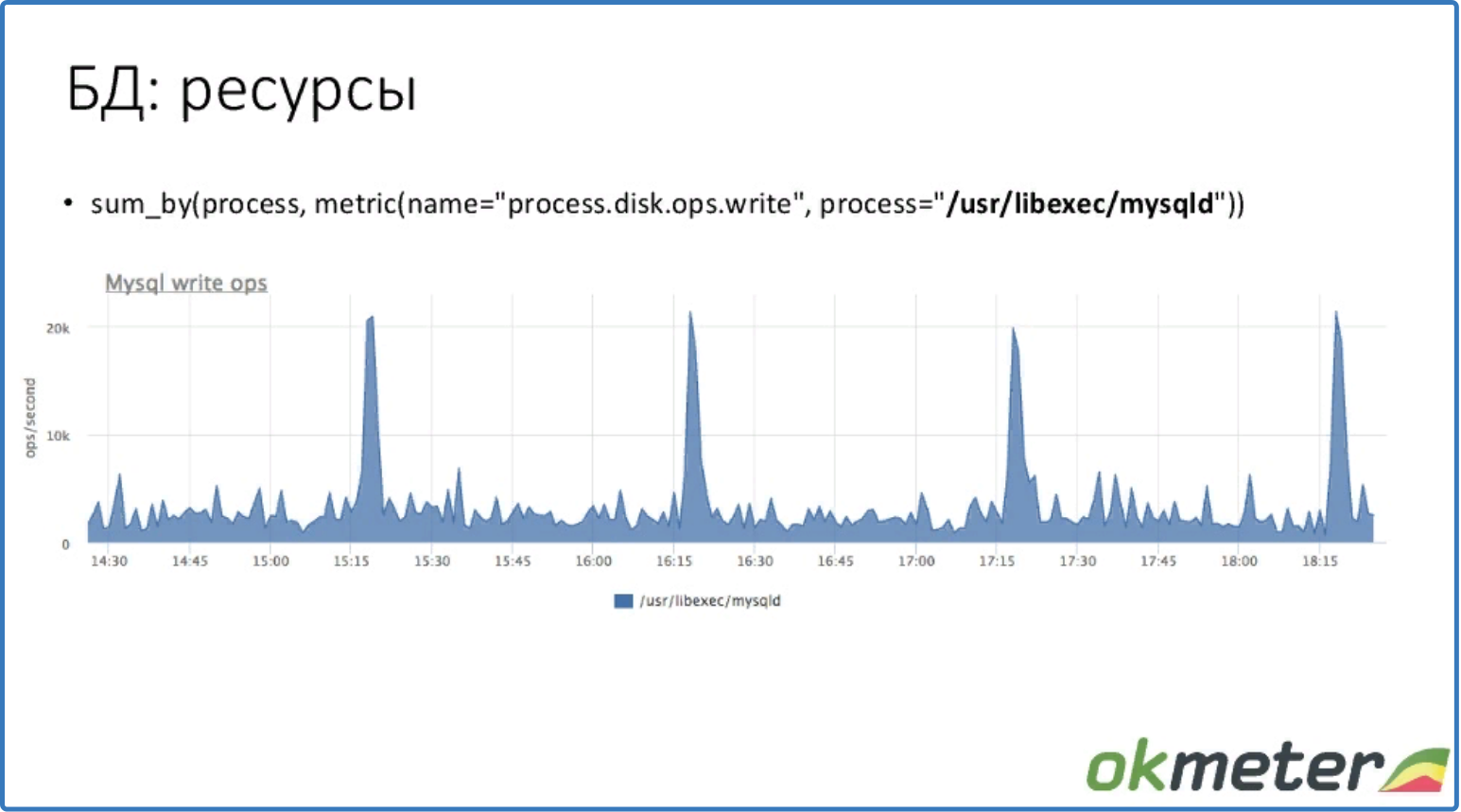
Видим, сколько MySQL выполняет операций записи на диск. Есть среднее значение и случаются пики.
Пример деградации базы данных по ресурсам. В случае если RAID батарейка недоступна, отключается write cash и latency записи дисков возрастает.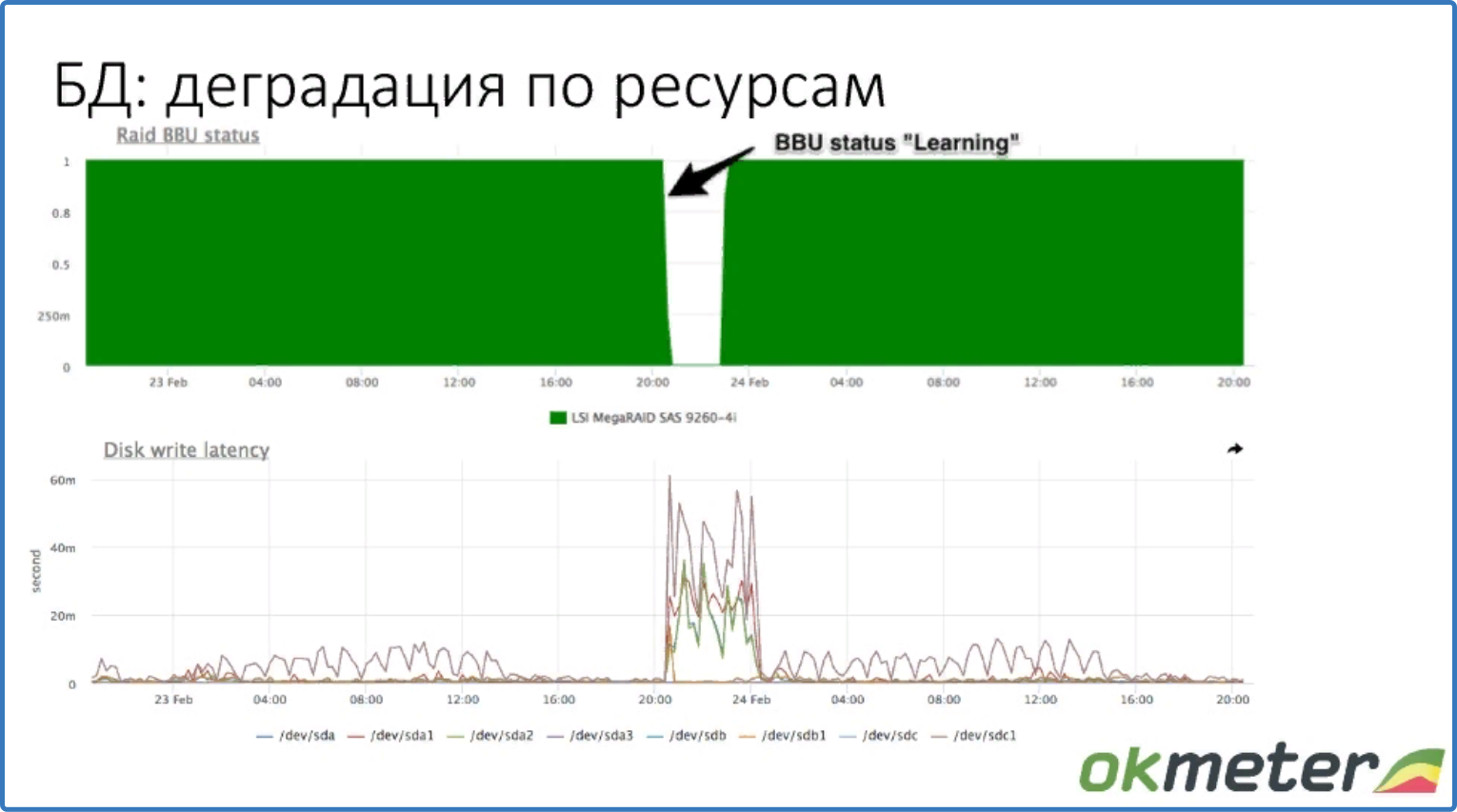
На графике видим случай деградации базы данных по ресурсам.
Возможности детализации мониторинга по запросам зависят от типа базы данных. Разные базы дают разную информацию о том, куда она тратит ресурсы и на какие запросы.
Для PostgreSQL есть модуль pg_stat_statements, который может отслеживать статистику выполнения сервером всех запросов. Покажет ресурсы по разным типам запросов. Несмотря на погрешность, дает актуальную информацию.
Для MySQL есть performance schema – возможность для мониторинга работы MySQL Server на низком уровне. Обеспечивает доступ к полезной информации работы базы данных на сервере. Оказывает минимальное влияние на производительность[1]. Реализована она сложнее, включена в мускул не так давно. Если делать запрос к неправильным view, можно перегрузить MySQL.
У Redis есть статистика, которая показывает потребление cpu для каждой команды.
У Cassandra есть тайминг по запросам к таблицам. Но так как каждой таблице соответствует один тип запроса, этого достаточно.
top (5, sum_by (command, counter_rate (metric (name = «redis.commands.seconds»))))
топ 5 ресурсов по запросам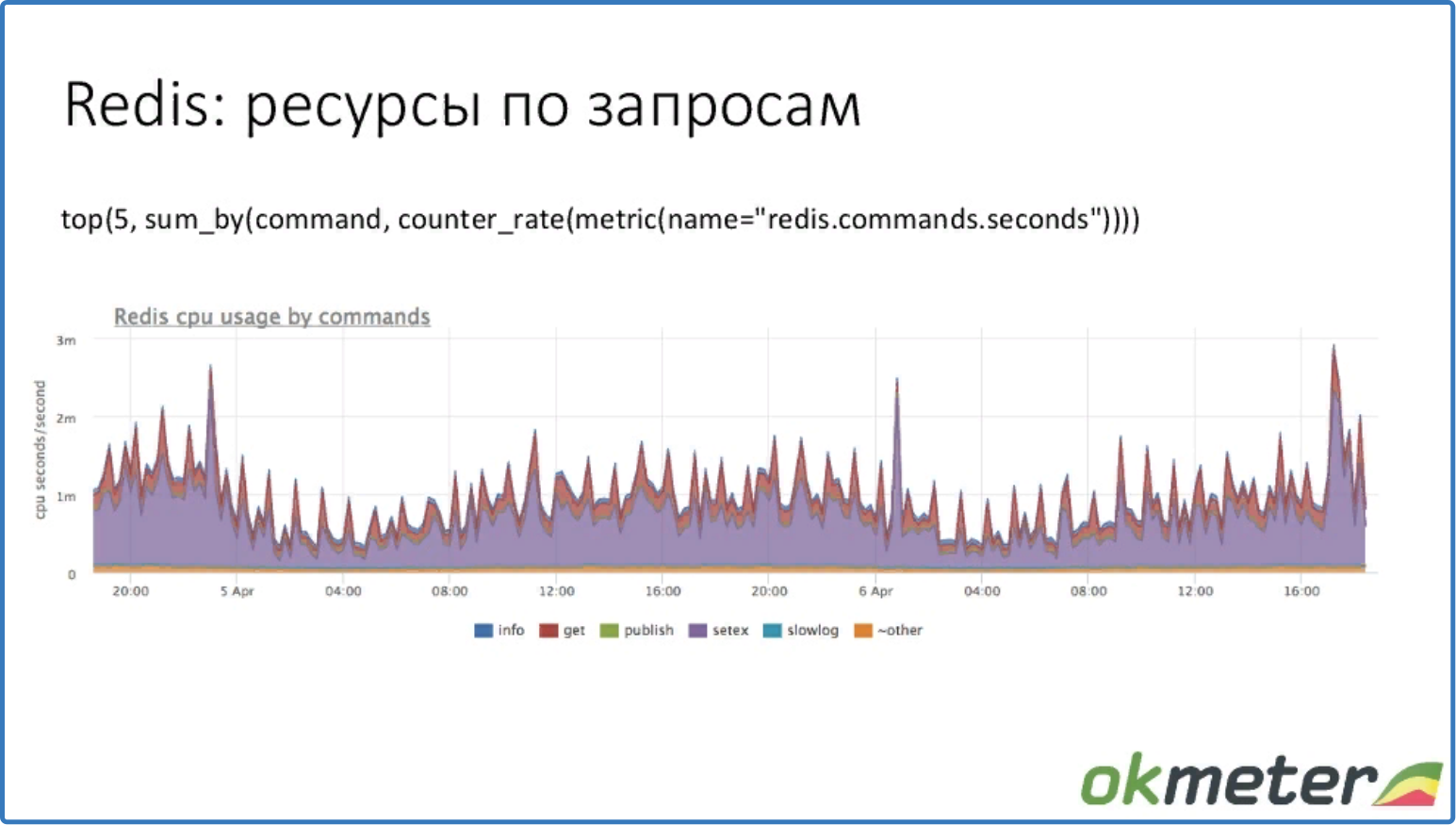
Видим, что команда setex использует больше ресурсов CPU.
top (5, sum_by (table, counter_rate (metric (name = "cassandra.table.ops.total_time", operation = "Read"))))
топ 5 latency по таблицам.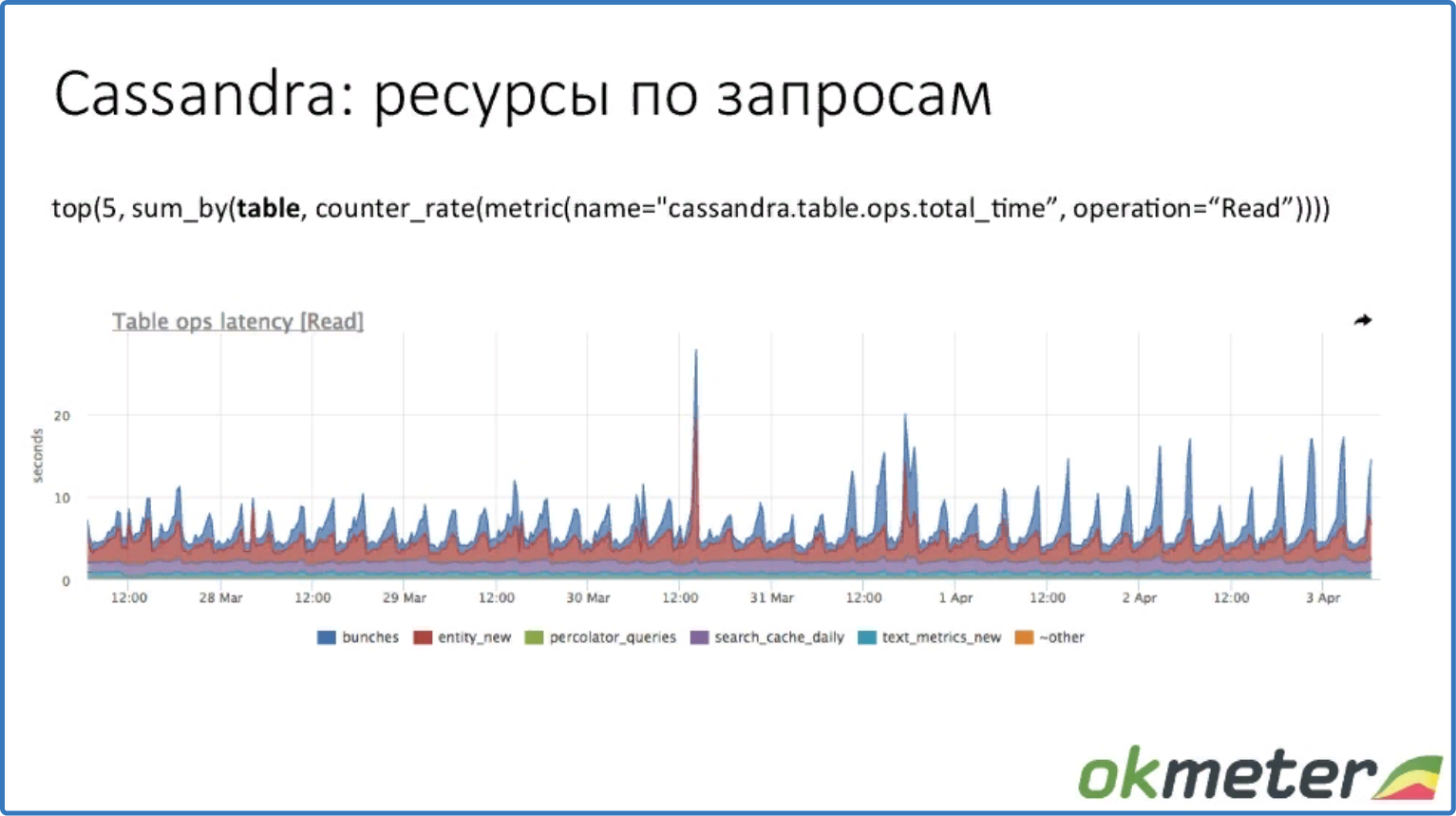
Видим, у какой таблицы (а значит у какого запроса) тайминги выше.
В итоге okmeter позволяет выполнить мониторинг любого проекта, не зависимо от его сложности. Первый уровень подходит для простых проектов. Второй уровень позволяет ускорить поиск причины проблем. Третий уровень позволяет максимально уменьшить время downtime.
Про workflow работы с инцидентами.
Severity алертов.
Описание severity алертов okmeter.
- CRITICAL – это критичные проблемы. Оповещение и коммуникация происходит по всем возможным каналам связи. Реагирование обязательно, эскалация происходит в кратчайшие сроки.
- WARNING – проблемы, которые не вызывают downtime, но влияют на проект. Оповещение и коммуникация возможны, но не обязательны. Эскалация в рамках обычного рабочего графика. Может помочь в решении проблем severity CRITICAL.
- INFO – сообщения об аномалиях и не состыковках. Без коммуникации – только лампочка об инциденте. Не требует эскалации, сигнализирует о работе системы. Может помочь в решении проблем severity WARNING и CRITICAL.
Подробнее про CRITICAL. Этот алерт будет разный для разных проектов. Примеры: сайт не работает; время ответа выросло, и пользователи начали уходить, так как долго ждут. Примеры ошибок бизнес логики: прием платежей, количество бронирований, падение потока покупок и др. Важно считать длительность CRITICAL. Если время действия CRITICAL алертов не равно времени downtime, значит severity установлен не верно. Нужно поднимать приоритет других алертов или определять новые.
Workflow необходим такой, чтобы минимизировать downtime. Решение проблемы отложить нельзя. Приоритет самый высокий. Причину алерта можно смотреть по WARNING и INFO.
Подробнее про WARNING. Это в основном характеристики, которые не оказывают существенный эффект на работу проекта, но при определенных обстоятельствах могут вызвать downtime. Примеры: диск кончается; один из сервисов недоступен или генерирует много ошибок; ошибки сетевого интерфейса; один сервер не отвечает, когда их много, swap IO процесса больше 1 Mb/s.
На сегодня для алертов severity WARNING у okmeter оповещение отключено. Сделано это, чтобы не было мониторинговой слепоты (когда оповещений слишком много, чтобы проанализировать).
Workflow. Проблема решается в рабочем графике, но не откладывается на неопределенный срок. Когда возникает алерт WARNING, на который реагировать не нужно, добавляем исключение. Частое появление алерта говорит о необходимой оптимизации или настройке самого алерта.
Подробнее про INFO. Те процессы, о которых хорошо знать, но реагировать на них не нужно. Например: %CPU больше 99%, Disk IO больше 99%. Данные показатели могут быть причиной downtime по другим метрикам, и при эскалации алерта CRITICAL необходимо просматривать INFO.
Workflow. Реагировать, выяснять причину алерта не нужно, оповещать тем более. Для бессмысленных алертов можно добавить исключения.
Работа с алертами и классификация.
Две основные цели мониторинга:
- вовремя обнаружить проблему,
- быстро выяснить причину.
Идеальный алерт показывает реальную причину проблемы. Добиться на практике этого тяжело. Поэтому нормально, когда администратор в процессе выяснения причины просматривает сотню предупреждений WARNING и INFO и определяет те, которые могут указать на причину. У алертов, которые никогда не помогают, а только мешают, нужно понижать severity.
Классификация инцидентов может также помочь уменьшить время downtime.
Пример классификации:
- релиз
- сервер
- host
- датацетр
- false positive
- другое
После инцидента алерт должен быть закрыт. Есть два варианта: он может закрываться автоматический или вручную. После закрытия инцидента, нужно выяснить причину. После эту причину классифицировать. Определить что нужно сделать, чтобы проблема не повторялась. Со временем система должна начать работать без сбоев.
Классификация ошибок помогает определить приоритеты. Смотрим, какой тип ошибок вызывает больше downtime, и определяем, в каком направлении нужно работать в первую очередь.
Итог
- Чем точнее работает мониторинг, тем стабильнее работает проект и больше получает довольных клиентов.
- Чем больше издержек и потерь терпит проект во время downtime, тем точнее и дороже нужна система мониторинга.
- Чем точнее мониторинг, тем быстрее выясняется причина проблем.
- Чем эффективнее настроен мониторинг, тем меньше затрат на него.
Внедрение систем мониторинга и сопровождение серверов, office@itfb.com.ua