Мы делаем мониторинг, несколько другим подходом, чем все это делают обычно. Мы очень много об этом рассказываем, и когда конкретного человека пытаемся в этом убедить, он убеждается. Я хочу рассказать о таком нашем подходе для того, чтобы, если вы будете делать мониторинг сами или уже делаете, то по нашим граблям можете пройти.
Про мониторинг серверов
Мы делаем то же самое, что и вы, но есть всякие «фишки»:
- детализация,
- куча преднастроенных триггеров, которые основаны на проблемах наших клиентов;
- автоконфигурация (чтобы это было не внедрение-внедрение, а поставил и работает).
Типичный клиент приходит к нам и у него есть две задачи. Первая – это понимать, что у него все сломалось из мониторинга (когда вообще ничего нет). Вторая задача – быстро чинить все это. Соответственно, он приходит в мониторинг за ответами, что у него происходит.
Первое, что делают люди, у которых ничего нет, ставят Pingdom, условные чекеры. У них фишка в том, что это можно сделать за пять минут. И все у вас начинает работать. Но в этом варианте есть проблемы с точностью, есть проблемы, что они пропускают проблемы. Для простенького сайта этого достаточно.
Второе, что мы пропагандируем — считать по логам по статистике реальных пользователей:
- сколько конкретный пользователь получает ошибки,
- сколько время ответа по пользователю.
Есть свои «минусы», но в целом такая штука работает.
Про мониторинг nginx
Мы сделали так, что любой клиент, который приходит, сразу ставит агенты на фронтенд. И у него сразу все автоматом подхватывается, начинает парсится, начинают показываться ошибки и т.д. Ему ничего не надо настраивать.
Но что делать, если у клиента нет в логе таймеров в стандартном ngnix? Это те 90% клиентов, которые не хотят знать время ответа их сайтов. Мы все время с этим сталкиваемся. В этом случае надо лог расширять, и тогда из коробки автоматом мы начинаем показывать еще и гистограммы. Это важный аспект того, что время надо мерять. Дальше, что мы оттуда выдергиваем? Про детализацию я говорил, но на практике (я не люблю разговаривать общими словами) мы снимаем метрики того, что напарсили, примерно в таких вот размерностях. То есть это не плоские метрики. Метрика называется «nginx.requests.rate» — сколько запросов в секунду. Но она детализирована:
- по хосту, с которого снялись,
- логу, с которого снялось,
- http-методу,
- http-статусу.
Про url. Естественно, это не каждый конкретный url со всеми аргументами. Мы не хотим снимать из лога 100 тысяч метрик, а только 1 тысячу. Поэтому пытаемся «url» нормализовать, если это возможно. И только для значимых «url», мы показываем отдельную гистограмму и т.д. Метрика превращается в юзабельные графики. Мы взяли все nginx.requests в секунду и разложили их по машинам всем, которые у нас есть. Результат: получили знание о том, как это у нас балансируется, сколько у нас суммарно rps, чтобы не в голове это все суммировать, а вот здесь. С другой стороны мы можем эту метрику профильтровать. Задать: покажи нам только пятисотки по реальному статусу. Напоминаю, это та же самая метрика. Или покажи нам пятисотки с разбивкой по «url».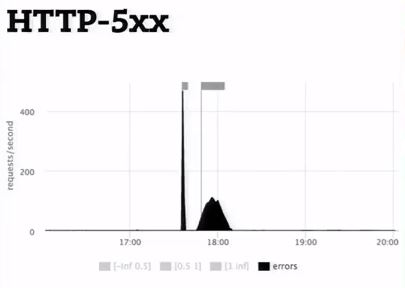
Еще мы снимаем из логов гистограмму. Это тоже метрика response_time.histogram, которая на самом деле rps. Только у него есть еще параметр level. Это как раз отсечка времени, в какой бакет попадает запрос. Мы рисуем такой запрос: просуммируй нам всю гистограмму и разложи по уровням – отдельно медленные запросы, отдельно быстрые, отдельно середнячок. Результат: имеем такую картинку, просуммированную по серверам, и мы ее можем уже разложить. Как видим, метрика одна и та же, но пользу из нее извлекаем совершенно по-разному. Еще один пример: можем задать, чтобы показала гистограмму только по url и api, начинающуюся с api. Таким образом, мы смотрим на гистограмму с разных сторон в зависимости от применения метрики.
Пара слов о тайминге в nginx
Есть request_time, который включает в себя от начала время и до передачи последнего байта в сокет клиенту, а есть upstream_response_time. Так вот их нужно мерить обе.
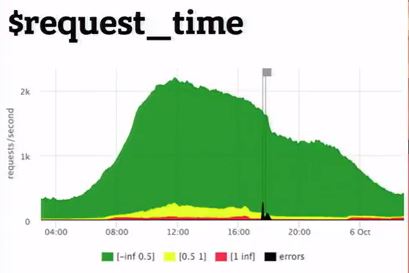
Потому что, если просто снимаем request_time, то там будем видеть «тупняки» из-за проблем, связанности клиента с вашим сервером. Вы увидите там «тупняки», если у вас настроен limit_request и клиент в бане, то есть limit_req+burst и клиент в бане (и вы не будете понимать, это вам сервер чинить или проблема в хостере). Соответственно, снимаем обе и примерно понятно, что происходит.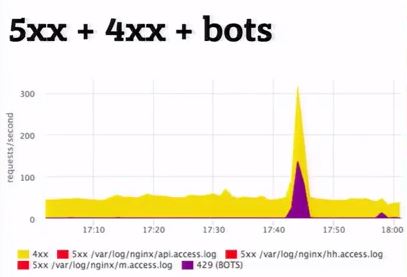
Благодаря перечисленным действиям, мы разобрались с задачей, узнать работает сайт или нет. Но практически всегда есть погрешности и неточности, на которые можно закрыть глаза.
Общие принципы мониторинга SOA
Когда мы говорим, что хотим замониторить многозвенную архитектуру. Потому что даже самый простой интернет-магазин кровли имеет фронтенд, битрикс и базу данных, то есть множество звеньев. Общий смысл в том, что нужно снимать какие-то показатели с каждого уровня: пользователь думает про фронтенд, фронтенд – про бэкенд, бэкенд – про соседние бэкенды, и все, что они думают про базу. Вот так по слоям, по зависимости, мы пробегаемся и покрываем все какими-то метриками, и получаем на выходе годное.
Почему же нельзя ограничиться одним слоем? Потому что, как правило, между слоями находится сеть под нагрузкой (когда сеть большая, она крайне нестабильная субстанция), поэтому там бывает всякое. Плюс могут врать те замеры, которые вы делаете на каком-то одном слое. Если вы делаете замеры на слое А и слое В, а они между собой взаимодействуют через сеть, то вы можете сравнивать их показания и находить какие-то аномалии и не состыковки.
Про Backend
Например, у нас есть некий там python ruby. Мы хотим понимать, как его замониторить, что с ним сделать, чтобы понимать быстро, что происходит. Напоминаем, мы перешли к минимизации даунтайма. Мы предлагаем стандартное понимание:
- сколько это поедает нам ресурсов;
- не уперлись ли мы в какой-нибудь лимит;
- что у нас происходит с райнтаймом и всякое-всякое.
И когда мы это уже все покрыли, нам интересно уже ближе к своему коду. Мы можем либо воспользоваться автоинструментилками, которые нам все это покажут, либо самостоятельно расставить таймеры, счетчики и т.д.
Про ресурсы
Мы снимаем с помощью стандартного агента показатели потребления ресурсов всеми процессами. Поэтому про Backend нам не надо отдельно париться. Мы просто берем и смотрим, сколько потребляет, например, процесс python на машинах помаски сколько потребляет cpu? Мы хотим понять, нет ли у нас разбалансировки где-то, не взорвалось ли что-то на одной машине. И мы видим показатель потребления – это суммарное от вчера к сегодня.
То же самое про память. Когда мы рисуем в таком виде, то есть мы выбираем python, RSS, суммируем по хостам. Сразу видно, что нигде не течет, везде память распределяет равномерно. И в принципе на свои вопросы мы ответ получили.
Пример рантаймов
У нас есть гошечка. Агент тоже на GO написан. И он присылает про себя метрики своего рантайма. Это в частности количество секунд потраченных коллектором GO в секунду. Соответственно, мы здесь видим, что у одних машин столько, у других машин столько. Увидели аномалию, пытаемся это объяснить.
Есть другая метрика рантайма: сколько памяти аллоцируется в единицу времени (чем больше памяти аллоцируется, тем больше нагрузка на горбыш коллектор). Соответственно, все объяснимо. Дальше мы уже по своим внутренним метрикам понимаем, почему мы столько памяти хотим на тех машинах и меньше на этих машинах.
Про инструментирование
Тут уже приходят инструменты различного типа. Так для php есть pinba. Тест на php про себя расказывает:
- сколько на cpu потратили такие-то срипты,
- сколько на память потратил на такие-то скрипты,
- сколько трафика отдано такими-то скриптами и т.д.
То есть мы показываем:
- топ-5 скриптов по потреблению cpu (Таким образом, мы сузили скол внимания настолько, что понимаем конкретно, какие шаги нужно сделать);
- топ-5 скриптов по трафику (если нас это парит, то мы идем и разбираемся).
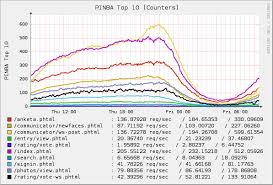
Это кусок внутреннего инструмента, когда мы ставили таймеры и измеряли. Мы сделали так, что у нас метрика количества суммарно проведенного времени cpu или в ожидании какого-либо ресурса раскладывается по хендлеру, который мы сейчас обрабатываем, и по значимым стадиям кода. Например, куски кода ждали кассандру, и мы им говорим: «Покажи нам расклад топ-5 стадий по хендлеру metric/query».
Благодаря полученным картинкам, становится понятно, что чинить.
Замечу, что мы трейсинг не делаем.
БД
База – тот же процесс. Он потребляет ресурсы. Поэтому в некоторых вариантах мы предлагаем проверять, не стало ли ресурсов меньше. Идеально понимать, что если база стала потреблять ресурсов больше, чем потребляла, понять конкретно, что в вашем коде изменилось, почему это произошло. Соответственно, по ресурсам также. Берем и смотрим, сколько процессов порождает у нас операции записей на диск. Видим, что у нас в среднем столько-то. Хорошо бы проверить, что ресурсов не стало меньше. Идеально разложить показатели потребления по запросам.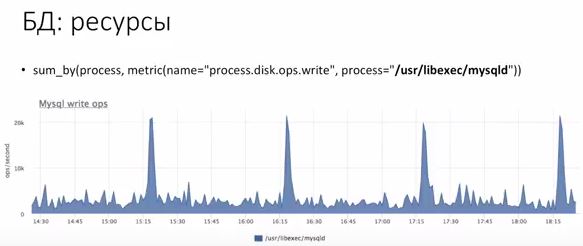
Про деградацию по ресурсам
Это происходит примерно так: у Raid батарейка перестала быть, как живая, в этот момент отключается рейд кэш, база начинает «тупить» при ожидании диска на запись. Соответственно, следует мониторить и ресурсы по запросам. Выполнение зависит от базы. База должна сама про себя уметь рассказывать, куда она тратит ресурсы, на какие запросы. Самый лидер по кайфовости – это PostreSQL, потому что он умеет показывать по разным типам запросов cpu*/disk io*/net*. Звездочки стоят потому, что все там с погрешностью, косвенно, но можно понимать, какой запрос жрет cpu. То есть запросы отдельно для cpu, диска io на чтение – на запись, какой запрос создал трафик.
В MySQL, если честно, все гораздо хуже. Иногда, если вы будете делать запросы к неправильным таблицам, вы можете там просадить мускуль. Рекомендую использовать только свежие версии, но это иногда дороговато.
В Redis есть статистика по командам. Можно видеть, что команда такая-то жрет cpu, команда такая-то не жрет cpu.
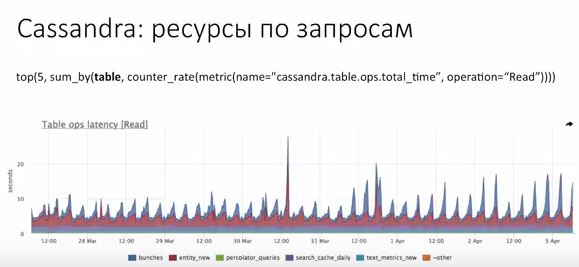
В Cassandra есть времена по запросам конкретных таблиц. Но она проектируется — 1 таблица = 1 тип запроса.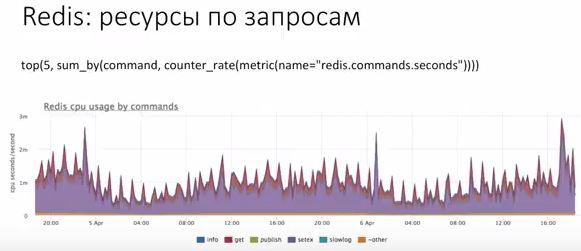
Продолжение читайте с следующей статье.