Для чего нужна оркестрация
Если ваша работа с данными в хранилище сводится к тому, чтобы сделать ad-hoc экспорт в Excel, то наверняка, что в оркестрации нет смысла. Однако если компания получает инсайты из данных, принадлежащих ей или это компания, построенная вокруг обработки данных, то процесс обязательно будет намного сложнее.nnК примеру, ваша компания обрабатывает большие массивы данных и предоставляет своим клиентам ценные советы: в таком случае процесс может выглядеть следующим образом. Каждую ночь в S3-бакете у вашего провайдера данных появляются файлы с «сырыми» данными. Но так получилось, что ваша компания выбрала Google Cloud Platform, потому в первую очередь необходимо перенести эти файлы в корпоративный Cloud Storage. После этого данные необходимо загрузить в хранилище данных BigQuery, где будет происходить дальнейшая обработка. Уже в BigQuery сложными SQL скриптами вы фильтруете ошибочные записи, производите агрегацию и обогащение данных.nnПредставим, что полученные данные необходимо каким-то образом провалидировать через сторонний API, но данных так много, что этот процесс нужно распараллелить, поэтому вам необходимо создать Dataproc кластер, куда будет отправляться определенный файл с кодом на Spark, а результат сохранить в специальную таблицу BigQuery. Когда результирующая таблица уже обновлена, вам необходимо триггернуть обновление Tableau дашборда, который уже подключен к этой же таблице, чтобы утром конечный пользователь видел новые данные.nnВозможны и гораздо более сложные пайплайны, где одни пайплайны зависят от других.nn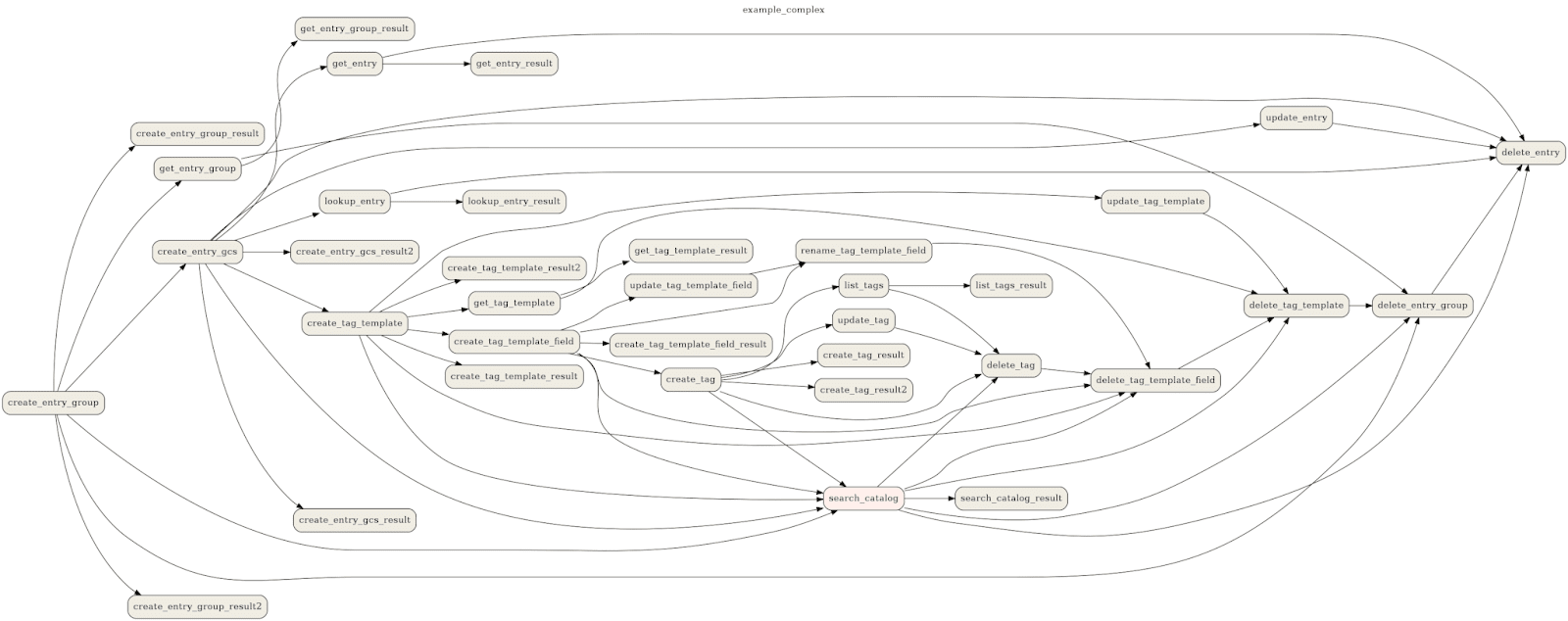 nnИменно для того чтобы описанный выше процесс происходил по графику и в определенной последовательности, вам нужен workflow менеджер. Последние несколько лет де-факто стандартным инструментом считается Apache Airflow.n
nnИменно для того чтобы описанный выше процесс происходил по графику и в определенной последовательности, вам нужен workflow менеджер. Последние несколько лет де-факто стандартным инструментом считается Apache Airflow.n
История
Airflow появился на свет в качестве внутреннего проекта компании Airbnb в 2014 году, но с самого начала он был open-source. Автором проекта является Максим Бушемин, который также разработал BI-инструмент с открытым кодом — Apache Superset. Уже в 2016 году проект переходит в Apache Incubator, а в 2019 году становится top-level проектом Apache Software Foundation. Проект написан на Python, на нем и описывается вся последовательность задач.n
Компоненты
Конфигурация зависит от того, какое количество параллельных задач должно выполнять этот инструмент. Уже от конфигурации зависит какие компоненты вам необходимы. Обязательные компоненты:n
- Metadata database — это база данных, где Airflow хранит всю необходимую цель-информацию о текущих и предыдущих задачах, их статусе и результате выполнения. Рекомендуется использовать СУБД Postgres для более стабильной и эффективной работы, однако, при необходимости можно подключить MySQL, MSSQL и SQLite (с ограничениями).
- Scheduler — компонент системы, парящий файлы с описанными пайплайнами и, при необходимости, передает на исполнение в Executor.
- Webserver — это приложение, использующее Flask и запускаемое через gunicorn. Основная роль этого компонента – это графическое отображение пайплайна и хода его выполнения.
Компоненты, зависящие от конфигурации и задач:n
- Triggerer — по сути, является имплементацией event-loop для асинхронных операторов, впервые появившихся в версии 2.2. Сейчас таких операторов очень мало, поэтому если вы не планируете их использовать, то нет необходимости запускать компоненту Triggerer.
- Worker – это модифицированный воркер из библиотеки Celery. Вы можете запустить столько воркеров, сколько вам нужно, но для этого нужно указать CeleryExecutor .
Исполнение
Очевидно, что Python-код, описывающий задачи и их порядок, должен где-то выполняться. Именно этим и занимается Executor. Airflow поддерживает несколько типов исполнителей:n
| Тип Executor’а | Где выполняются задачи |
| SequentialExecutor | Локально, в основном потоке выполнения |
| LocalExecutor | Локально, в отдельных процессах операционной системы |
| CeleryExecutor | В Celery воркерах |
| DaskExecutor | В узлах Dask кластера |
| KubernetesExecutor | В Kubernetes подах |
nДля production-а чаще всего используются CeleryExecutor и KubernetesExecutor. Это нужно учесть и при построении пайплайна, чтобы между отдельными задачами не было зависимостей, кроме прописанных в самом пайплайне. То есть каждая задача будет выполняться в собственной изолированной среде и, скорее всего, в разных физических компьютерах, поэтому последовательность задач скачивания файла на диск и загрузить файл в облачное хранилище не будет рабочей.n
Архитектуры
Как вы уже догадались, Apache Airflow – это достаточно гибкий инструмент, поэтому его можно конфигурировать точно под конкретные требования. Однако существуют две общеупотребительные архитектуры: single-node и multi-node.nn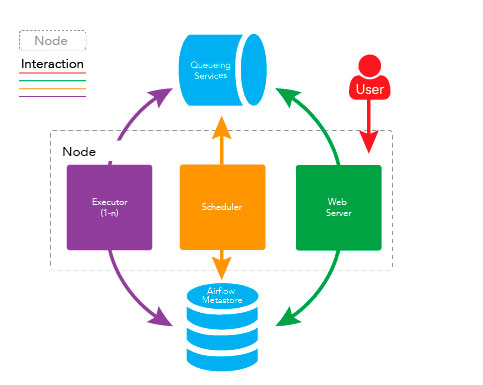 nn
nn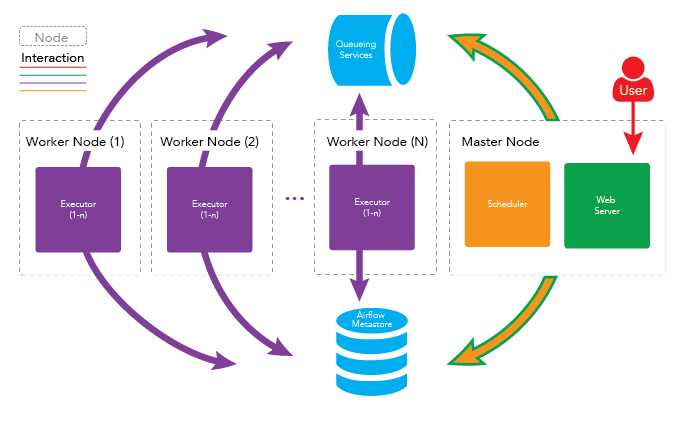 n
n
Установка
Есть несколько разных способов установить и запустить Airflow.n
- n
- Через менеджер пакетов PIP.
nНаверное, это самый удобный способ. Сначала придется установить все необходимые зависимости, затем настроить и запустить СУБД по вашему выбору. Конечно, вы можете выбрать SQLite, однако тогда придется использовать SequentialExecutor и пожертвовать параллельностью выполнения задач. После этого желательно создать и активировать виртуальное окружение для Python и уже тогда можно приступать к установке и запуску Airflow компонентов.n
python -m pip install apache-airflownairflow webservernairflow schedulern
Трудно перечислить, сколько может возникнуть нюансов при этом варианте. Если вы используете Linux или MacOS, то наверняка проблем будет не так много. Однако для Windows придется самостоятельно компилировать и устанавливать некоторые дополнительные библиотеки, поэтому лучше сразу использовать WSL .nn2. Через отдельные Docker-контейнеры.nnНаверное, что этот метод – не самый удобный для установки на локальной машине, но может подойти, если вам нужно вручную настраивать Airflow-кластер на своих bare-metal серверах.n
docker run … postgresndocker run … apache/airflow schedulerndocker run … apache/airflow webservern
3. Через docker-compose.nnЭто наиболее удобный способ локального запуска. Для этого нужно скомпоновать свой docker-compose . yaml файл, или воспользоваться уже готовыми вариантами и выполнитьn
docker-compose upn
Более подробно об этом способе написано в одном из официальных туториалов .nn4. Через Astronomer CLI.nnПоследний способ, который я бы хотел назвать, не универсален, но он прекрасно подходит для локальной разработки, особенно если ваша компания использует managed-версию Apache Airflow от компании Astronomer. Для начала работы необходимо установить Astronomer CLI и выполнить:n
astro dev initnastro dev startn
Кроме удобства настройки локальной разработки через Astronomer CLI очень легко деплоить.n
Managed версии
Учитывая популярность этого инструмента, появление managed-версий у облачных провайдеров было только вопросом времени. Сейчас Airflow находится на Google Cloud Platform под названием Cloud Composer и на AWS как Managed Workflows for Apache Airflow (MWAA). Также облачную версию предлагает провайдер Cloud Data Lake Qubole.nnОтдельно хотелось бы рассмотреть компанию Astronomer, основанную и в которой работают топ-контрибьюторы опенсорсного проекта. Также эта компания проводит много вебинаров, посвященных этому инструменту, и имеет два подготовительных курса по сертификации с Apache Airflow.n
Интерфейс
Галерею скриншотов можно посмотреть здесь .n
Концепт
Перейдем к рассмотрению основных сущностей, которые нужно знать, когда вы почитаете работу по Airflow.n
Сущности
Основной сущностью workflow является DAG (directed acyclic graph) – ориентированный ациклический граф, объединяющий все задачи в один пайплайн. Понятие DAG-а встречается и в других популярных инструментах, например в Apache Spark.nn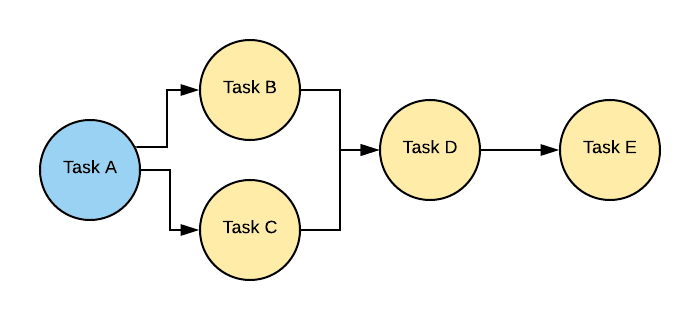 nnУзлы этого графа — Task , являющийся экземпляром класса Operator . Операторы условно можно разделить на:n
nnУзлы этого графа — Task , являющийся экземпляром класса Operator . Операторы условно можно разделить на:n
- Action operator — выполняет определенное действие, как DataprocSubmitSparkJobOperatorи
- Transfer operator — переносит данные из одного места в другое, как S3ToGCSOperator
- Sensor operator — ожидает определенного события, как BigQueryTablePartitionExistenceSensor
В основном пайплайны запускаются с определенной регулярностью, поэтому существует понятие Task Instance — экземпляр определенного оператора с меткой времени, когда произошел запуск пайплайна. Для примера:n
- PythonOperator – выполняет определенную python функцию.
- BashOperator – запускает bash команду или скрипт.
- PostgresOperator – выполняет SQL запрос в PostgreSQL.
- KubernetesPodOperator – запускает pod на кластере и выполняет определенные команды.
А через веб-интерфейс есть возможность создавать Variables вроде переменных окружения и Connections – данные необходимые для подключения для внешних ресурсов.nnОбе сущности хранятся в базе метаданных и доступны из всех компонентов системы, причем пароли для Connection хранятся в зашифрованном виде.nnТакже нужно упомянуть и о Hook – интерфейсе для работы с внешними сервисами. Хуки – это обертки над популярными библиотеками для работы с определенным инструментом, например, хуки для работы с реляционными СУБД используют SQLAlchemy, а хуки для работы с AWS используют библиотеку boto3.nnХуков и операторов сейчас насчитывается около 850, поэтому актуальна идея реестра для удобного поиска. Как раз это недавно было имплементировано в Astronomer Registry. Но даже если вы не нашли нужный вам оператор, то вы можете с легкостью написать свой, следуя классу BaseOperator.n
Дополнительные библиотеки
Airflow имеет модульную структуру и для полноценной работы в определенной конфигурации требуется дополнительные библиотеки, которые могут устанавливаться вместе с Airflow. Например, если вы хотите настроить CeleryExecutor, вам необходимо также установить библиотеки celery и redis, если вы хотите настроить другую аутентификацию, то вам необходимы соответствующие библиотеки. Это все core extras.nnСейчас Airflow поддерживает работу с более чем 50 сторонними ресурсами, но нет смысла их все одновременно устанавливать. То есть, если для работы вам нужна только интеграция с Snowflake и AWS, то вы устанавливаете соответствующие интеграции и не ставите библиотеки для работы, например, с Oracle, Neo4j и MongoDB. Это providers extras.nnБолее подробно об этом в официальной документации.n
Создание DAG-ов
Основные моменты
Мы пришли к основному вопросу: как выглядит пайплайн в Airflow.nnСначала импортируем необходимые библиотеки и функции.n
import requestsn import pandas as pdn from pathlib import Path nfrom airflow. models import DAG nfrom airflow. Operators . python import PythonOperatorn
Далее напишем две python-функции, которые производят определенные действия. Но хочу уточнить, что такой подход нежелателен потому, что чаще всего для production используется CeleryExecutor или KubernetesExecutor, поэтому вторая функция вернет ошибку, потому что в ее окружении не будет файла.n
def download_data_fn():n url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv' n resp = requests. get (url)n Path ( 'titanic.csv' ). write_text (resp.content. decode ())nndef pivot_data_fn ():n df=pd. read_csv ( 'titanic.csv' )n df=df. pivot_table (index= 'Sex' , columns= 'Pclass' , values= 'Name' , aggfunc= 'count' )n df. reset_index (). to_csv ( 'titanic_pivoted.csv' )n
Ну и дальше создаем экземпляр DAG-а и экземпляры операторов – таски. Первое условие dag_idдолжно быть уникальным в пределах всего деплоймента. Вторая – все task_idтакже должны быть уникальными в пределах одного DAG-а.n
with DAG ( dag_id= 'titanic_dag' , schedule_interval= '*/9 * * * *' ) as dag:n download_data = PythonOperator(n task_id= 'download_data' ,n python_callable=download_data_fn,n dag=dag,n )nn pivot_data = PythonOperator(n task_id= 'pivot_data' ,n python_callable=pivot_data_fn,n dag=dag,n )n
Начиная со второй версии Airflow, нет необходимости давать на вход оператору экземпляр DAG-а, если оператор находится в контексте DAG-а.nnСледующим шагом указываем зависимости между тасками, то есть порядок их выполнения.n
download_data >> pivot_datan# pivot_data << download_data n# download_data .set_downstream(pivot_data) n# pivot_data.set_upstream(download_data)n
Замечу, что каждый из вышеуказанных вариантов создает ту же зависимость, и вы можете использовать любой из них. Рекомендуется использовать либо только вызовы метода, либо только битшифт оператор.nnНаписанный файл должен быть в директории, где Airflow ищет DAG. По умолчанию это $AIRFLOW_HOME/dags. После этого уже scheduler будет ставить этот пайплайн в очередь исполнения, а Executor будет выполнять этот пайплайн каждые девять минут.n
Taskflow API
Также в Airflow 2.0 появилась возможность значительно упростить использование функций.n
import requestsn import pandas as pdn from pathlib import Path nfrom airflow. models import DAG nfrom airflow. decorators import tasknnwith DAG (dag_id= 'titanic_dag' , schedule_interval= '*/9 * * * *' ) as dag :n @task n def download_data ():n url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv' n resp = requests. get (url)n Path ( 'titanic.csv' ). write_text (resp. content . decode ())nn @task n def pivot_data ():n df=pd. read_csv ( 'titanic.csv' )n df=df. pivot_table (index= 'Sex' , columns= 'Pclass' , values= 'Name' , aggfunc= 'count' )n df. reset_index (). to_csv ( 'titanic_pivoted.csv' )n
В этом примере декоратор @task принимает на вход python-функцию и возвращает экземпляр PythonOperator. При этом зависимости прописываются следующими способами:n
pivot_data(download_data())n # download_data_op = download_data() n # pivot_data_op = pivot_data() n # download_data_op >> pivot_data_opn
Немного о start_date и schedule_interval
Почти у каждого, кто только начинает работу с Airflow, возникают проблемы с пониманием интервалов и дат. Перед тем, как начать, стоит уточнить, что Airflow использует только UTC в процессе работы.nnКаждый DAG принимает такие параметры как start_date и schedule_interval . start_date, определяет, с какого времени можно запускать пайплайн, а schedule_interval показывает, с какой периодичностью необходимо запускать. Интересно, что schedule_interval может быть относительным, если мы указали timedelta или абсолютным, если это cron expression.nnВ первом случае, запуск пайплана состоится в start_date + schedule_interval , но execution_date будет равна start_date . Во втором же случае логика scheduler-а следующая – первый execution_date – это первая дата и время после start_date , удовлетворяющая условиям schedule_interval , а первый запуск пайплайна, соответственно, это следующие такие дата и время.nn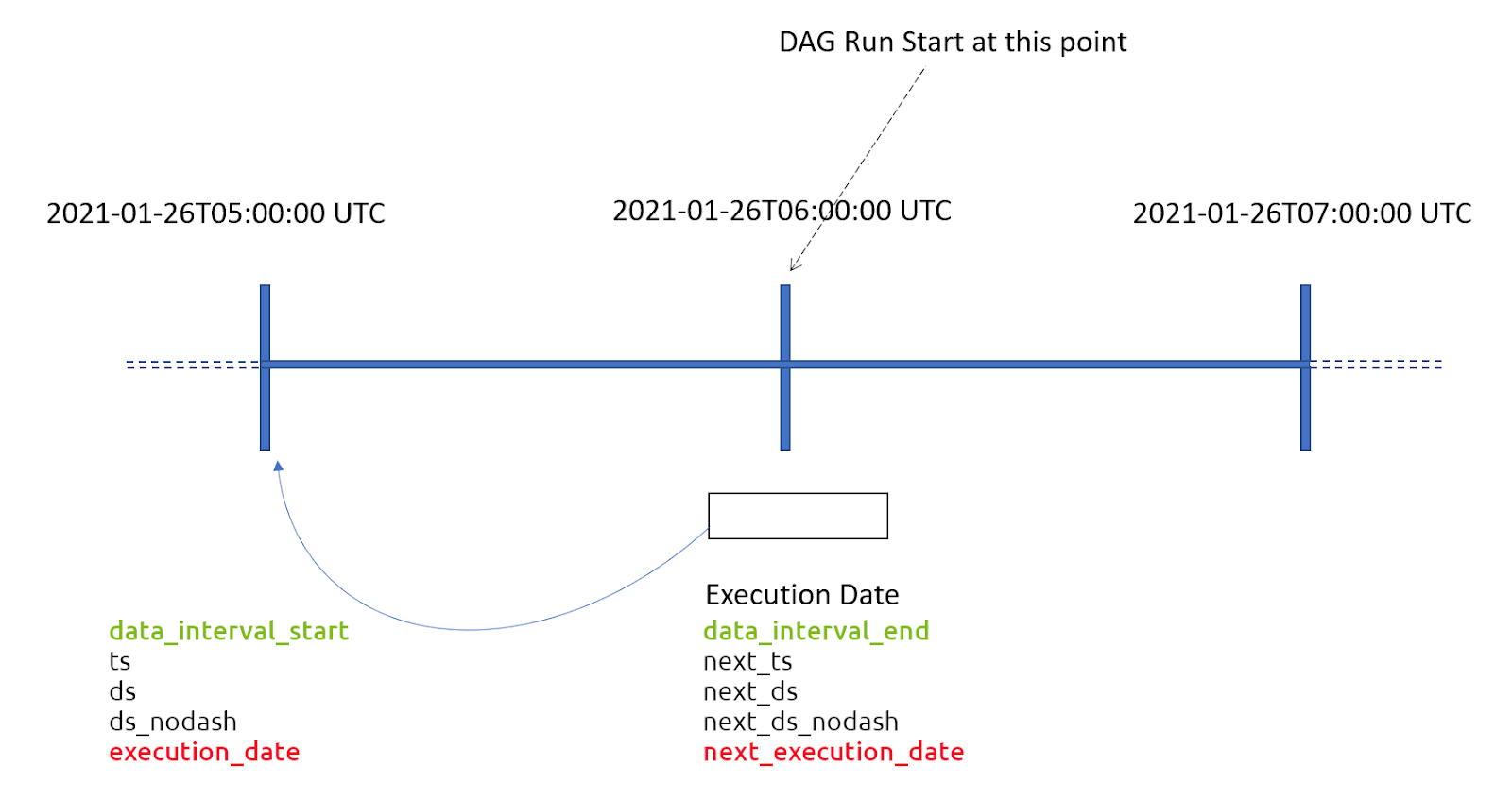 nnЧтобы описать расписание, изображенное на рисунке выше, мы можем использовать:n
nnЧтобы описать расписание, изображенное на рисунке выше, мы можем использовать:n
- schedule_interval = timedelta(hours=1) и start_date = datetime(2021, 01, 26, 5, 0, 0)
- schedule_interval = ‘0 * * * *’, а start_date может быть в любое время от datetime(2021, 01, 26, 4, 0, 1) до datetime(2021, 01, 26, 5, 0, 0)
Из-за определенной путаницы, разработчики решили отказаться от этого названия и приняли решение, что у каждого запуска будут два параметра data_interval_start и data_interval_end . Первый показывает, когда последний раз запускался пайплайн, а второй – текущий запуск.n
XComs
Что делать, если между задачами дополнительные зависимости, а не только условие, что «Задача Б» должна запускаться после «Задачи Б»?nnЭту проблему решают XComs ( cross-task comminications ). Благодаря этому механизму задача может записывать в базу метаданных любые данные, а другая задача – их читать. Возьмем за основу прошлый пример, но в этом случае допустим, что название файла может быть произвольным и будет генерироваться первой задачей.n
def download_data_fn(**context):n filename = 'titanic.csv' n url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv' n resp = requests. get (url)n Path (filename). write_text (resp.content. decode ())n #context[ 'ti' ]. xcom_push (key= 'filename' , value=filename) # option 1 n return filename # option 2nnndef pivot_data_fn (ti, **context):n #filename=ti. xcom_pull (task_ids=[ 'download_data' ], key= 'filename' ) # option 1 n filename = ti. xcom_pull (task_ids=[ 'download_data' ], key= 'return_value' ) # option 2 n df = pd. read_csv (filename)n df=df. pivot_table (index= 'Sex' , columns= 'Pclass' , values= 'Name' , aggfunc= 'count' )n df. reset_index (). to_csv ( 'titanic_pivoted.csv' )nnwith DAG (dag_id= 'titanic_dag' , schedule_interval= '*/9 * * * *' ) as dag:n download_data = PythonOperator (n task_id= 'download_data' ,n python_callable=download_data_fn,n provide_context=True,n )nn pivot_data = PythonOperator (n task_id= 'pivot_data' ,n python_callable=pivot_data_fn,n provide_context=True,n )nn download_data >> pivot_datan
Как видим, существует несколько способов записывать данные в XCom, однако следует быть внимательными и передавать через этот механизм лишь небольшие данные. Во-первых, это замедлит работу базы, а превышение определенных лимитов, зависящих от СУБД, вызовет ошибку, во-вторых – следует помнить, что Airflow – это оркестратор, и он не предназначен для обработки данных.n
Недостатки
Трудно ошибиться, если сказать, что у каждого довольно сложного инструмента есть определенные особенности, к которым можно привыкнуть, и определенные недостатки, очень мешающие. Для меня таким недостатком есть сложный процесс разработки.nnТо есть для того чтобы начать разрабатывать, необходимо установить и запустить Airflow локально. А для того чтобы оттестировать, необходимо прописать все Connections и Variables. Количество первых может считаться десятками, а вторых – сотнями. Это не говоря о том, что для тестирования необходимо иметь development и/или staging окружение.n
Альтернативы
Несмотря на лидирующие позиции Airflow как workflow менеджера, у него есть конкуренты. Все, что я хотел бы привести в пример, являются open-source проектами и имеют определенное сообщество вокруг себя.nnНаиболее перспективным сейчас выглядит Dagster , на это намекающий раунд А инвестиций в компанию Elementl , занимающуюся разработкой и коммерциализацией этого инструмента. Еще совсем недавно основным конкурентом Airflow можно было считать инструмент Prefect , который тоже разрабатывается одноименной компанией. Стремительно теряет позиции Spotify Luigi , однако все еще используется во многих компаниях из-за легкости в использовании. Ну и в конце я хотел бы упомянуть Apache Oozie как представителя экосистемы Apache Hadoop. Этот проект очень медленно развивается, но имеет узкую нишу. Также я бы посоветовал обратить внимание на такие инструменты как Flyte , разрабатываемый компанией Lyft и Azkaban., в котором много контрибьют HashiCorp.nnНаверное, к альтернативам можно было бы отнести и такие инструменты как dbt , Apache NiFi , а также AWS Glue, Azure Data Factory, Databricks Live Tables и множество подобных инструментов для построения ETL/ELT пайплайнов.nnПеревод статьи Дмитри Казанжи.