У нас было много возможностей увидеть немало кластеров в нашем многолетнем опыте работы с kubernetes (как управляемым, так и неуправляемым — в GCP, AWS и Azure), и мы видим, что некоторые ошибки повторяются. В этом нет ничего постыдного, мы сделали большинство из них тоже!
Я постараюсь показать те, которые мы видим очень часто, и немного расскажу о том, как их исправить.
Ресурсы — запросы и ограничения
Это определенно заслуживает наибольшего внимания и первого места в этом списке.
Запрос ЦП обычно либо не установлен, либо установлен очень низким (так что мы можем разместить много модулей на каждом узле), и узлы, таким образом, перегружены. Во время высокой нагрузки процессорные ресурсы узла полностью используются, и наша рабочая нагрузка получает только «то, что он запросил» и регулирует нагрузку на ЦП , что приводит к увеличению задержки приложения, тайм-аутам и т. д.
BestEffort (не делайте так):
resources: {}
очень низкий процессор (не делайте такого):
resources:
requests:
cpu: "1m"
С другой стороны, ограничение ЦП может излишне ограничивать блоки, даже если ЦП узла используется не полностью, что опять-таки может привести к увеличению задержки. Существует открытая дискуссия о квоте CPU CFS в ядре Linux и дросселировании ЦП на основе установленных ограничений ЦП и отключении квоты CFS. Ограничения процессора могут вызвать больше проблем, чем решить.
Перегрузка памяти может доставить вам больше проблем. Достижение лимита ЦП приводит к регулированию, а при достижении лимита памяти ваш модуль перестанет работать. Вы когда-нибудь видели OOMkill ? Да, это тот, о котором мы поговорим. Хотите минимизировать, частоту возникновения? Не перегружайте свою память и используйте Guaranteed QoS (Quality of Service), устанавливающее запрос памяти, равный пределу, как в примере ниже.
Burstable (более вероятно получить OOMkilled):
resources:
requests:
memory: "128Mi"
cpu: "500m"
limits:
memory: "256Mi"
cpu: 2
Гарантия:
resources:
requests:
memory: "128Mi"
cpu: 2
limits:
memory: "128Mi"
cpu: 2
Так что может помочь вам при настройке ресурсов?
Вы можете увидеть текущее использование процессора и памяти модулями (и контейнерами в них), используя metrics-server . Скорее всего, вы уже запускали его. Просто выполните это:
kubectl top pods
kubectl top pods --containers
kubectl top nodes
Однако они показывают только текущее использование. Это замечательно, когда есть возможность получить приблизительное представление о цифрах, но вы в конечном итоге захотите увидеть эти показатели использования во времени (чтобы ответить на такие вопросы, какое было использование процессора в пике, вчера утром и т. д.). Для этого вы можете использовать Prometheus , DataDog и многие другие. Они просто получают метрики с сервера метрик и сохраняют их, а затем вы можете запросить и построить график.
VerticalPodAutoscaler может помочь вам автоматизировать этот ручной процесс — отслеживая использование процессора / памяти во времени и устанавливая новые запросы и ограничения на основе этой основе.
Эффективно использовать ваши ресурсы- непростая задача. Это как играть в тетрис все время. Если вы обнаружите, что платите много за вычисления при низком среднем использовании (скажем, ~ 10%), возможно, вы захотите использовать продукты на основе AWS Fargate или Virtual Kubelet, которые используют больше серверной модели оплаты / оплаты за использование, которая может быть дешевле для вас.
Тесты доступности и готовности
По умолчанию тесты доступности и готовности не указаны. И иногда так и остается …
Но как еще ваш сервис может быть перезапущен, если возникла неисправимая ошибка? Как балансировщик нагрузки знает, что конкретный модуль может начать обрабатывать трафик? Или обрабатывать больше трафика?
Люди обычно не знают разницы между этими двумя показателями.
- Датчик доступности перезапускает ваш модуль, если он выходит из строя
- Проверка готовности отключается при сбое модуля сбоя от службы kubernetes (вы можете проверить это
kubectl get endpoints), и больше не отправляется трафик на него, пока проверка не будет успешно завершена
И ОБА ЗАПУЩЕНЫ В ТЕЧЕНИИ ВСЕГО ЖИЗНЕННОГО ЦИКЛА. Это важно.
Люди часто думают, что датчики доступности запускаются только в начале, чтобы определить, когда модуль готов и может начать обслуживать трафик. Но это только один из его вариантов использования.
Другой — сказать, что если во время жизни модуля он перегрелся, обрабатывая слишком большой трафик (или дорогостоящие вычисления), чтобы мы не посылали ему больше работы и не давали ему остыть , тогда проверка готовности завершается успешно и мы снова начинаем посылать больше трафика . В этом случае (при отказе датчика готовности) выход из строя также датчика живучести будет очень контрпродуктивным. Зачем вам перезапускать модуль, который здоров и выполняет много работы?
Иногда отсутствие определения любого датчика лучше, чем определение их неверно. Как уже упоминалось выше, если датчик живучести равен датчику готовности, у вас большие проблемы. Возможно, вы захотите начать с определения только одного датчика готовности, поскольку тесты жизнеспособности опасны.
Не пропускайте тесты, если какая-либо из ваших общих зависимостей не работает, это приведет к каскадному отказу всех модулей.
LoadBalancer для каждого http сервиса
Скорее всего, у вас есть больше http-сервисов в вашем кластере, которые вы хотели бы представить внешнему миру.
Если вы предоставляете услугу kubernetes как a type: LoadBalancer, ее контроллер (в зависимости от поставщика) будет предоставлять и согласовывать внешний LoadBalancer (не обязательно L7 loadbalancer, более вероятно, L4 lb), и эти ресурсы могут дорого обойтись (внешний статический адрес ipv4, вычисления, посекундные ценообразование…).
В этом случае совместное использование одного внешнего loadbalancer может иметь больше смысла, если вы предоставляете свои услуги как type: NodePort. Или еще лучше, развертывать что — то вроде Nginx-ингрессии-контроллер (или traefik ) является единственной NodePort конечной точкой подвергающейся воздействию внешнего loadbalancer и маршрутизации трафика в кластере, основываясь на kubernetes Ingress ресурсов.
Другие внутрикластерные (микро) сервисы, которые общаются друг с другом, могут обмениваться данными через сервисы ClusterIP и обнаружение DNS-сервисов «из коробки». Будьте осторожны, не используйте их общедоступные DNS / IP-адреса, так как это может повлиять на их задержку и стоимость облака.
автоматическое масштабирование кластера с некубернетским охватом
При добавлении и удалении узлов в/из кластера вы не должны учитывать некоторые простые метрики, такие как использование этих процессоров процессором. При планировании модулей вы решаете на основе множества ограничений планирования, таких как сходство модулей и узлов, порчи и допуски, запросы ресурсов, QoS и т.д. Наличие внешнего автомасштабатора, который не понимает эти ограничения, может быть проблематичным.
Представьте, что запланирован новый модуль, но запрашивается весь доступный процессор, и модуль застрял в состоянии ожидания. Внешний автоскалер видит среднее используемое в настоящее время процессора (не запрашивается) и не будет масштабироваться (не добавит еще один узел). Pod не будет запланирован.
Масштабирование (удаление узла из кластера) всегда сложнее. Представьте, что у вас есть модуль с состоянием (с подключенным постоянным томом), и поскольку постоянные тома обычно являются ресурсами, которые относятся к определенной зоне доступности и не реплицируются в регионе, ваш пользовательский автоскалер удаляет узел с этим модулем, и планировщик не cможет запланировать его на другой узел, так как он ограничен единственной зоной доступности с вашим постоянным диском в нем. Pod снова застрял в состоянии ожидания.
Сообщество широко использует cluster-autoscaler, который работает в вашем кластере и интегрирован с большинством API-интерфейсов большинства поставщиков общедоступных облаков, понимает все эти ограничения и будет масштабироваться в упомянутых случаях. Он также выяснит, может ли он корректно масштабироваться, не затрагивая какие-либо ограничения, которые мы установили, и сэкономит вам деньги на вычислениях.
Не используя IAM / RBAC
Не используйте пользователей IAM с постоянными секретами для машин и приложений, создавайте временные секреты с использованием ролей и учетных записей служб.
Мы часто это видим — жесткое кодирование доступа и секретные ключи в конфигурации приложения, никогда не меняя секреты, когда у вас есть Cloud IAM под рукой. Используйте роли IAM и учетные записи служб вместо пользователей, где это необходимо.

Пропустите kube2iam, перейдите непосредственно к ролям IAM для учетных записей служб, как описано в этом посте https://blog.pipetail.io/posts/2020-04-13-more-eks-tips/ .
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::123456789012:role/my-app-role
name: my-serviceaccount
namespace: default
Одна аннотация. Это было не так сложно?
Также не предоставляйте учетные записи служб или профили экземпляров adminи cluster-adminразрешения, когда они не нужны. Это немного сложнее, особенно в k8s RBAC, но все же стоит усилий.
Самостоятельное сродство c pods
Запуск, например, 3-х реплик некоторого развертывания, узел отключается и все реплики с ним. А? Все реплики работали на одном узле? Разве Kubernetes не должен был быть волшебным и обеспечивать HA ?!
Вы не можете ожидать, что планировщик kubernetes будет применять антиаффинные средства для ваших модулей. Вы должны определить их явно.
// omitted for brevity
labels:
app: zk
// omitted for brevity
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
Вот и все. Это обеспечит планирование модулей на разные узлы (это проверяется только во время планирования, а не во время выполнения, следовательно, requiredDuringSchedulingIgnoredDuringExecution).
Мы говорим о podAntiAffinity на разных именах узлов, а topologyKey: "kubernetes.io/hostname"не на разных зонах доступности. Если вам действительно нужен правильный HA, копайте глубже в этой теме.
без подкупа бюджета
Вы выполняете производственную нагрузку на kubernetes. Ваши узлы и кластер должны время от времени обновляться или выводиться из эксплуатации. PodDisruptionBudget (pdb) — это своего рода API для гарантий обслуживания между администраторами кластера и пользователями кластера.
Убедитесь, что создали, pdbчтобы избежать ненужных перерывов в обслуживании из-за опустошения узлов.
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper
В качестве пользователя кластера вы говорите администраторам кластера: «эй, у меня здесь есть служба zookeeper, и независимо от того, что вам нужно делать, я бы хотел, чтобы по крайней мере 2 реплики были всегда доступны».
Более подробно здесь, в этом посте https://blog.marekbartik.com/posts/2018-06-29_kubernetes-in-production-poddisruptionbudget/
больше арендаторов или envs в общем кластере
Пространства имен Kubernetes не обеспечивают какой-либо сильной изоляции .
Люди, кажется, ожидают, что если они разделят рабочую нагрузку, не относящуюся к prod, к одному пространству имен и prod к пространству имен prod, то одна рабочая нагрузка никогда не повлияет на другую. Можно достичь некоторого уровня справедливости — запросов и пределов ресурсов, квот, приоритетов — и изоляции — сходства, допуски, порты (или выборки узлов) — для «физического» разделения рабочей нагрузки в плоскости данных, но это разделение довольно сложное.
Если вам нужно иметь оба типа рабочих нагрузок в одном кластере, это будет достаточно сложно. Если вам это не нужно, а наличие другого кластера относительно дешево для вас (как в общедоступном облаке), поместите его в другой кластер, чтобы достичь гораздо более высокого уровня изоляции.
externalTrafficPolicy: кластер
При этом очень часто весь трафик направляется внутри кластера в службу NodePort, которая по умолчанию имеет externalTrafficPolicy: Cluster. Это означает, что NodePort открыт на каждом узле в кластере, так что вы можете использовать любой из них для связи с желаемой службой (набором модулей).
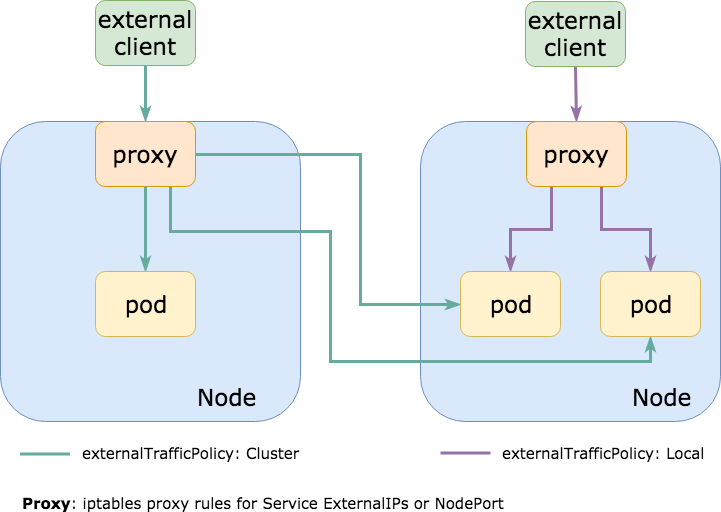
Чаще всего фактические модули, на которые ориентирована служба NodePort, запускаются только на подмножестве узлов . Это означает, что если я общаюсь с узлом, на котором не запущен модуль, он перенаправит трафик на другой узел, что вызовет дополнительный сетевой скачок и увеличит задержку (если узлы находятся в разных AZ / центрах обработки данных, задержка может быть довольно высокой и к этому добавляется дополнительная стоимость).
Настройка externalTrafficPolicy: Localслужбы kubernetes не будет открывать этот NodePort на каждом узле, а только на узлах, где на самом деле работают модули. Если вы используете внешний балансировщик нагрузки, который проверяет работоспособность своих конечных точек (как это делает AWS ELB ), он начнет отправлять трафик только на те узлы, куда он должен идти, улучшая вашу задержку, накладные расходы на вычисления, исходящие счета и работоспособность.
Скорее всего, у вас есть что-то вроде traefik или nginx-ingress-controller , представленного как NodePort (или LoadBalancer, который также использует NodePort) для обработки маршрутизации вашего входящего http-трафика, и этот параметр может значительно уменьшить задержку при таких запросах.
Кластеры + чрезмерное напряжение в плоскости управления
Вы ушли от того, чтобы называть свои серверы Anton , HAL9000 и Colossus, чтобы генерировать случайные идентификаторы для своих узлов, но вы начали называть свой кластер по имени?
Вы начали с Proof Of Concept с Kubernetes, назвали кластер «тестирование» и все еще используете его в продуктиве, и все боятся его трогать? (правдивая история)
Pet clusters — это не весело, и вы можете время от времени рассматривать возможность удаления своего кластера, попрактиковаться в Аварийном восстановлении и позаботиться о своей панели управления. Бояться трогать панель управления — плохой знак.
С другой стороны, трогать его слишком сильно тоже нехорошо. Когда со временем панель управления становится медленной , скорее всего, вы либо создаете много объектов, даже не подозревая об этом (очень часто при пользовании настройками по умолчанию, которые вы не меняете в конфигурационных / секретных файлах, и в итоге вы получаете тысячи объектов в плоскости управления) или вы постоянно очищаете и редактируете множество вещей из kube-api (для автоматического масштабирования, cicd, мониторинга, журналов событий, контроллеров и т. д.).
Также проверьте свои управляемые kubernetes, предлагающие «SLA» / SLOs и гарантии. Поставщик может гарантировать доступность плоскости управления (или ее подкомпонентов), но не задержку p99 запросов, которые вы ему отправляете. Другими словами, вы можете сделать kubectl get nodesи получить правильный ответ в течение 10 минут, и это все еще не нарушает гарантию обслуживания.
Бонус: используйте тег
Это классика. Я чувствую, что в последнее время я не вижу этого очень часто, так как многие из нас слишком много обожглись, и мы перестали использовать :latestи начали прикалывать версии. Ура!
У ECR есть отличная особенность неизменяемости тегов , которую обязательно стоит проверить.
Резюме
Не ожидайте, что все работает автоматически — Кубернетес — не серебряная пуля. Плохое приложение будет плохим приложением даже на kubernetes (возможно, даже хуже, чем плохое, на самом деле). Если вы не будете осторожны, вы можете столкнуться с большими сложностями, стрессом и медленным управлением и отсутствием стратегии DR. Не ожидайте многопользовательской аренды и высокой доступности. Потратьте некоторое время на то, чтобы сделать ваше приложение облачным.