Если у нас есть сервер который неизвестно как работает и на нем отсутствуют системы мониторинга. А нам не медленно, и хочется чтобы все работало побыстрее. Для этого нужно определить, что является бутылочным горлышком в конкретной ситуации.
Процессор
Для начала воспользуемся командой top: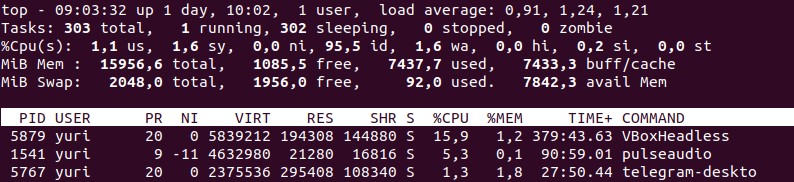
Смотрим на значения load average, us, id, wa и столбец %CPU:
• load avegare представлен тремя цифрами, которые обозначают среднее значение загрузки сервера за 1, 5 и 15 минут. Чем меньше значение, тем лучше работает сервер. Данная характеристика помогает оценить нагрузку сервера в минимальные сроки. Значения не должны превышать общего числа процессоров в системе.
• us — загрузка пользовательскими процессами.
• id — процент времени простоя процессора, значение должно быть большим, в норме — от 80. но сильно зависит от конкретной задачи запущенной на сервере.
• wa — ожидание операций ввода/вывода, чем ниже, тем лучше (в противном случае процессор слишком долго ожидает ответы от диска или сети).
• в столбце %CPU можно увидеть процессы и сколько процессорных ресурсов они потребляют.
Похожая утилита, но с дополнительными возможностями (поиск и фильтрация, вывод дерева процессов, групповые операции над процессами завершение процессов и т.д.), большей наглядностью и возможностью настройки — htop.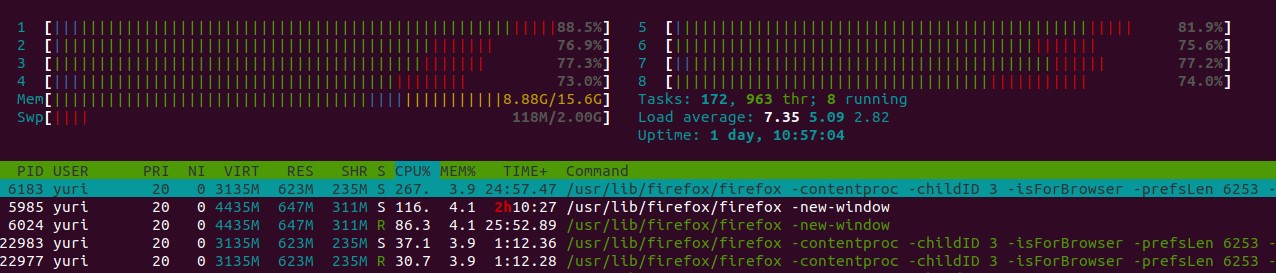
Также удобно использовать atop, позволяет мониторить не только процессор а также память, диск, сетевую активность(с модулем), а также хранить историю.
Для общей оценки нагрузки на процессор можно использовать команду vmstat обычно установлена по умолчанию. При использовании без параметров выведет среднее значение с момента последней загрузки. В данном примере используется ключ -w для широкого представления а также параметр 5 который выводит результат сбора за последние 5 секунд. В колонке CPU видно что среднее время ожидания процессора 91% что является высоким показателем но за последние 5с всего 68% , но эта статистика по всем ядрам и процессорам.
Память
Использование памяти можно посмотреть с помощью команды free (установлена по умолчанию). Для более читабельного формата, примените ключ -h:
В результате работы команды интересуют 2 значения: free и swap (used). Free показывает, сколько сейчас свободно оперативной памяти. Маленький размер свободной памяти не говорит о каких-то проблемах, но за ним нужно следить, чтобы убедиться, что памяти будет хватать даже при пиковых нагрузках. Важно обратить внимание на использование файла подкачки (swap). Если если значение swap больше нуля, значит часть данных не помещается в оперативную память и вытесняется на диск, а так как дисковые операции чтения и записи гораздо медленнее аналогичных для памяти, то падает производительность всей системы. Но в данном примере не стоит переживать из-за свапа так как в предыдущем примере мы видели на сриншоте команды vsstat поле swap c 2 параметрами
si (swap in) — количество блоков в секунду, которое система считывает из раздела или файла swap в память;
so (swap out) — и наоборот, количество блоков в секунду, которое система перемещает из памяти в swap.
В идеале, значение обоих должно быть около нуля или, по крайней мере, не более 10 блоков/секунду.
Ту же информацию с некоторыми подробностями можно получить и другим путём:
Дисковая подсистема
Сначала стоит проверить наличие свободного места. Проверяем командой df. Как и в случае с free, используйте ключ -h для более читабельного вида: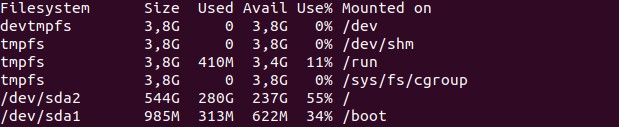
Старайтесь всегда иметь достаточно свободного места (Avail) на используемых разделах. И не забывайте про инноды ведь они могут закончится раньше чем свободное место. Посмотреть командой df -i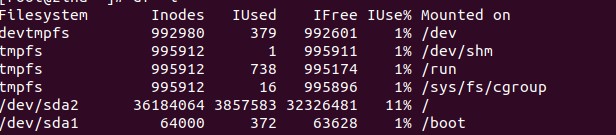
Дисковая подсистема может создавать задержки, если объём одновременно читаемой или записываемой информации превосходит пропускную способность диска. Это можно определить с помощью утилиты iotop.
Важные для нас показатели: Actual DISK READ и Actual DISK WRITE. Если значения высоки (десятки и сотни M/s), то обратите внимание в таблице на процессы, которые производят наибольшую нагрузку и проанализируйте, почему это происходит и как нагрузку можно снизить (кеширование, отключение лишних логов, настройка базы данных и т.д.).
Сеть
Чтобы посмотреть объёмы сетевого трафика в реальном времени, можно использовать простейшую утилиту cbm, или atop

Но если вы хотите узнать IP-адреса устройств, обменивающихся трафиком с вашим сервером. Это можно сделать с помощью утилиты iftop.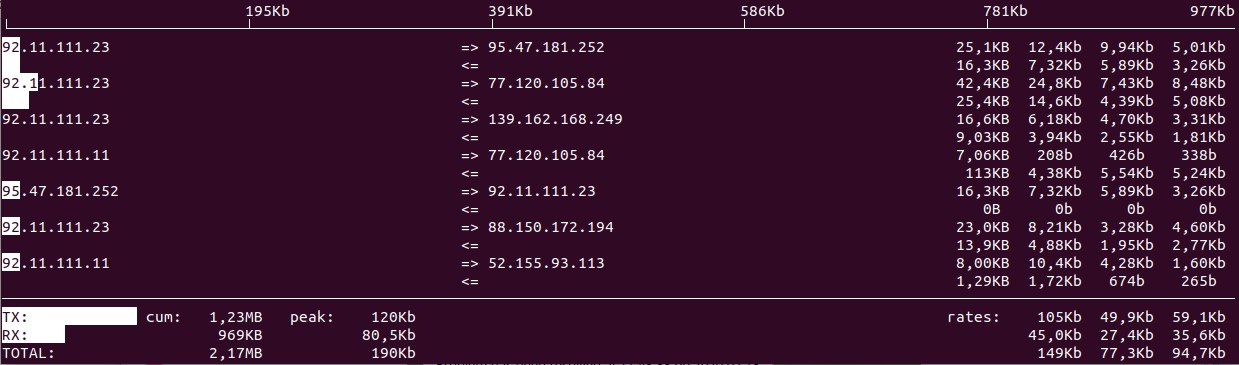
С сетью возможна только одна проблема — среднее значение Total близко к пропускной способности сетевого интерфейса сервера. Если это так, то вероятно, пора либо бороться с DDoS-атакой, если это она, либо планировать масштабирование.
Вывод:
Итак подведем итог, что проверять на сервере
- Проверяем общую нагрузку на систему с момента загрузки утилитой vmstat.
- Смотрим параметры загрузки системы с помощью atop. Если необходимо дополнительно посмотреть нагрузку на диск или на сеть то устанавливаем iotop и iftop coответственно.
- Смотрим нагрузку на дисковую подсистему и сеть
- Проверяем параметры настройки основных сервисов установленных на сервере. (например apache, mysql, java)
- Если есть возможность настроить atop на логирование состояний и провести тестирование нагрузкой.
Если не получается найти проблему самостоятельно, обращайтесь к нам, наши специалисты обязательно найдут и устранят проблему с производительность.