Изначально перед нами стояла задача обеспечить всех участников процесса разработки, тестирования и внедрения неким инструментом, который позволяет создавать однотипные тестовые окружения быстро и в автоматическом режиме.
Дополнительным требованием было обеспечить возможность обмениваться конфигурациями этих окружений между командами, работающими в разных городах, иногда не имеющими доступа к площадкам друг друга.
Это позволит разворачивать тестовые стенды идентичных конфигураций в любом месте, в любое время и в любом количестве, не мешая группам, одновременно работающим над решением различных проблем.
Еще такой подход позволяет при наличии проблем у пользователя убедиться, что конкретный набор софта в конкретной конфигурации работоспособен, и, возможно, стоит поискать проблему в конфигурации инфраструктуры пользователя.
Дополнительным ограничением при выборе технологий выступил факт внедренной и успешно используемой системы управления виртуализацией Proxmox Virtual Environment (PVE).
Ориентированная на простоту использования, она не имеет готового инструментария для создания и управления достаточно сложными конфигурациями, которые требовались для решения наших задач. Например, на момент начала реализации нашего проекта PVE не имел API для управления параметрами Cloud-Init.
Выбор пути решения
Вариант с использованием контейнеризации и сопутствующих решений с Docker compose и Kubernetes не подходил, т.к. наши пользователи в большинстве своем применяют наш продукт не в контейнеризованной среде, и проводить тестирование мы хотим в условиях максимально приближенных к реальности.
С другой стороны, можно взять чистый REST-API Proxmox, обвешаться шелл-скриптами, которые будут разворачивать окружения, а все, что нельзя сделать через REST, делать скриптами через ssh. Это решение самое быстрое и в большинстве случаев еще и рабочее, но его масштабирование на возросшие потребности в будущем, как правило, требует достаточно больших переработок в дизайне и кодовой базе.
В итоге как компромиссный вариант было принято решение остановиться на использовании одной из существующих систем управления конфигурацией. Не вдаваясь в детали, остановились на Ansible.
Пожалуй, основным критерием выбора именно этого инструмента стала его простота и понятность для большинства системных администраторов. А это ведет к тому, что большинство людей из целевой аудитории без серьезных затрат своего времени смогут вносить в проект необходимые им изменения для решения своих задач и при желании поделиться своими наработками.
Разработка дизайна
Простота Ansible имеет и обратную сторону. Из коробки она не предоставляет всего функционала, необходимого нам для решения задачи, а значит, придется собрать свой конструктор, попутно дорабатывая напильником в нужных местах. Но, с другой стороны, такой подход позволяет делать именно то, что нужно нам, не ограничиваясь рамками готовых решений.
Первое, с чего стоит начинать новый проект — это с понимания того, что вы хотите получить в итоге и как этим будут пользоваться люди. Наш подход разделяется на следующие сущности: приложения, стек и окружение.
Проект находится в ранней стадии разработки. Сейчас он выполняет большинство задач, которые мы планировали
Далее рассмотрим их более подробно.
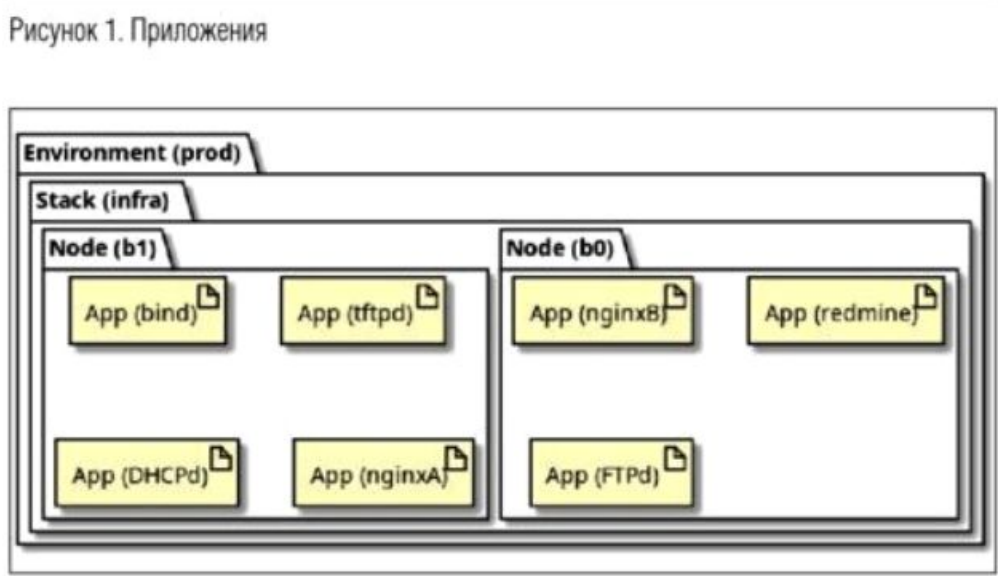
Приложения
Приложение (арр) — это сервис, имеющий интерфейс, посредством которого с приложением будут общаться люди или другие сервисы. Приложение должно быть куда-то развернуто, сконфигурировано относительно среды и запущено. Также у него могут быть зависимости от других приложений, и в таком случае порядок развертывания и запуска может быть важен.
Очевидно, что для работы наших приложений необходима среда исполнения (например, операционная система), которая, в свою очередь, должна быть установлена на железе (реальном или виртуальном). В терминологии нашего проекта «среда исполнения» называется «нода» или «node».
Несколько приложений вполне могут быть установлены на одну ноду, но, как правило, для полноценного тестирования в условиях, приближенных к реальным, таких нод несколько, и на каждой из них «живет» свой набор приложений.
Ноды должны обеспечивать возможность доставлять сообщения от одних приложений к другим. Часто это обеспечивается посредством TCP/IP в среде Ethernet, и это тоже требует отдельной непротиворечивой и воспроизводимой конфигурации. Множество нод с их конфигурацией называется «стек» или «stack».
Стеки
Стек (stack) — описание множества (не пустого) нод и их конфигураций, необходимых для установки и функционирования приложений.
Конфигурация нод включает в себя:
- тип платформы: голое железо, Proxmox (QEMU), LXC, etc.
- архитектура: х86, х86_64, Elbrus, etc.
- количество ядер процессора;
- ограничение по оперативной памяти;
- количество и параметры сетевых интерфейсов;
- имя образа или шаблона, из которого будет развернута среда исполнения;
- описание и параметры необходимых сетевых интерфейсов.
И еще множество дополнительных параметров, если они необходимы в конкретном случае.
А также один из основных параметров «количество таких нод в стеке». Это позволяет разворачивать достаточно большие стеки для интеграционного тестирования различных конфигураций.
Например, достаточно легко описать стек из одного сервера с контроллером домена, трех реплик, двух клиентов на базе десктопного дистрибутива, и двух клиентов на базе серверного дистрибутива.
После чего прогнать против этого стека интеграционные тесты и в случае неудавшегося тестирования отправить конфигурацию этого стека разработчику, который получит точно такое же окружение и сможет гораздо быстрее найти и исправить ошибку либо определит, что что-то не так с конфигурацией какого-то из приложений.
После выявления и исправления причин сбоев можно повторить процедуру, но уже в конфигурации с большим числом реплик или вообще без них, с другими клиентами или новыми версиями приложений и т.д. Но и подготовка нод требует наличия дополнительной конфигурации. Например, адреса сервера PVE,
аутентификационные данные, публичные ключи доступа, которые необходимо положить на ноды, и т.д. Все это описывается в последней сущности «Окружение» или «env».
Окружение
Окружение (env) — это набор параметров, общих для всего стека. Как правило, это адрес локального зеркала пакетов, параметры доступа к Proxmox, список нод, на которых можно разворачивать контейнеры той или иной архитектуры, список ssh-ключей, которые необходимо зарегистрировать на всех нодах кластера.
Реализация
Попытка реализации вышеописанного подхода была предпринята нашей командой во внутреннем проекте с рабочим названием «Infra». В первую очередь этот проект призван помогать решать стоящие перед нами задачи и нацелен на то, чтобы стать надежным и удобным инструментом в создании процесса непрерывной интеграции (CI). Давайте рассмотрим некоторые проблемы, с которыми мы столкнулись, и пути их решения, которые нам удалось найти.
Первая проблема, которая появилась в самом начале, — как хранить секретные данные и обеспечить к ним доступ всех членов команды?
Простая ситуация: у нас есть сервер Proxmox, на нем мы хотим разворачивать тестовые стенды как руками с ноутбуков разработчиков, так и автоматически в рамках CI. В процессе деплоя необходимо создавать пользователей домена с паролями, задать пароль для администратора и использовать прочие данные, которые посторонним показывать нельзя. С другой стороны, нам необходимо иметь возможность передавать проблемную конфигурацию заинтересованным лицам. В идеале она должна быть передана через открытые каналы, например через публичный git-репозиторий.
Решение, примененное нами, состоит из двух частей. Поля с секретными данными в самой конфигурации мы шифруем через стандартный механизм ансибла Ansible Vault симметричным ключом, этот ключ кладем в базу утилиты pass, в которой он шифруется асимметричными PGP-ключами всех заинтересованных лиц.
После этого мы можем публиковать и конфигурацию, и базу pass на публичных ресурсах.
При запуске развертывания происходит обратная процедура: у пользователя стандартными средствами системы запрашивается пароль от секретного PGP-ключа, которым зашифрован пароль в базе pass, полученный ключ передается в ансибл через временный файл, и уже с помощью этого ключа расшифровываются секретные поля в конфигурации.
Такой подход позволяет легко предоставлять доступ к базе ключей новым участникам команды, не изменяя конфигурации самого стека. Прекращение доступа для участника также возможно, но уже требует смены ключей в конфигурации стека, что в принципе решается скриптами.
Второй проблемой стала необходимость соблюдения порядка деплоя приложений в некоторых нетривиальных конфигурациях. Один из методов решения — ждать, пока заработает необходимый сервис, и после этого продолжать установку зависимого приложения. Но с этим подходом есть пара проблем.
Предположим, что приложение А зависит от сервиса В. Во-первых, не ясно, сколько нужно ждать. Некоторые приложения могут стартовать в первый раз достаточно долго. Но если поднять порог ожидания, то в случае каких-то проблем с сервисом В мы впустую будем тратить время на ожидание. и весь деплой в конце концов упадет по тайм-ауту. Заметить проблему с сервисом В во время исполнения установки достаточно проблематично, т.к. лог ансибла при параллельном исполнении задач порою выглядит как неприличное месиво.
Определить причину тайм-аута тоже не так-то просто, т.к. она может быть не в проблемах с сервисом В. а, например, в сетевой недоступности ноды с сервисом В для ноды с приложением А. В общем, метод рабочий, но спектр применений сильно ограничен.
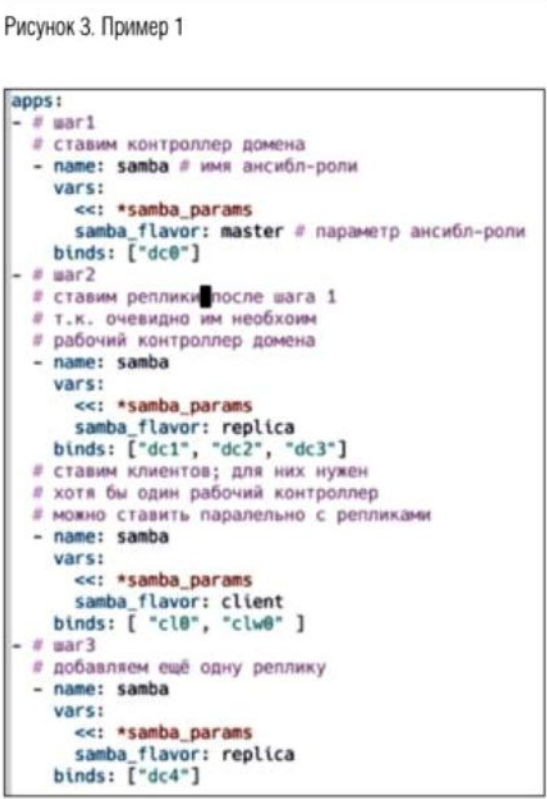
В качестве альтернативы был реализован метод поэтапной установки. Так называемые шаги или steps. В общем виде он представляет собой список списков пар (сервис, нода). Задачи из нижнего списка будут исполнены параллельно, но эти списки будут перебираться последовательно и в строго заданном порядке.
В данном примере (см. рис. 3) мы хотим сначала развернуть контроллер домена на ноде dc0, после успешного завершения мы разворачиваем три контроллера домена в режиме реплики dc1, dc2, dc3 и параллельно с ними разворачиваем два клиента домена на нодах сI0 и clw0.
Для ввода клиентов в домен достаточно одного рабочего контроллера, поэтому можно сократить время деплоя, устанавливая клиентов одновременно с репликами. И в последнем, третьем, шаге мы добавляем еще одну реплику на ноде dc4.
Такой подход к описанию конфигурации позволяет достаточно свободно менять шаги местами, разбивать шаг на более мелкие или. наоборот, объединять несколько шагов в один, реализовывая различные тестовые сценарии. Также достаточно легко добавлять запуск тестов почти в любое место деплоя, а не только последним шагом.
Несколько слов о том, откуда взялись ноды dc0, dc1, clw0 и т.д. За их появление отвечает стек. На рис. 4 представлен пример конфигурации шести однотипных нод.
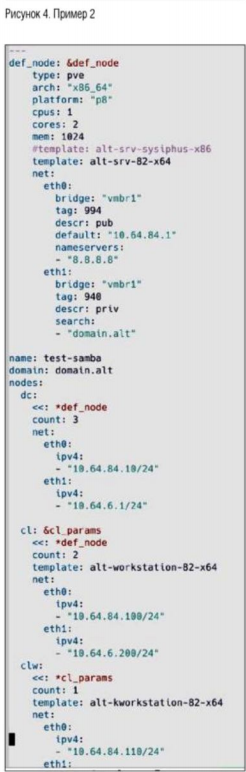
Интересным моментом тут являются поля count и ipv4 в параметрах сетевого интерфейса. Фактически мы описываем, что хотим три ноды с именами dc0, dc1. dc2 (имена будут сгенерированы из имени ключа dc и порядкового номера 0..count-1), поднять их нужно на PVE по два ядра на каждую ноду и по гигабайту памяти.
Также необходимо добавить два сетевых интерфейса eth0 и eth1. Первый должен входить в 994-й VLAN на мосту vmbrl, и адреса должны быть назначены начиная с 10.64.84.1. То есть нода dc0 будет иметь адрес 10.64.84.10, нода dс1 — 10.64.82.11 и т.д. Второй интерфейс по аналогии, только другой VLAN-тег и другие адреса. Ноды для клиентов конфигурируются по аналогии, но разворачиваются с другого шаблона (параметр template).
Таким образом, мы достаточно легко можем менять количество тех или иных нод в стеке, конфигурацию их интерфейсов, адресные сетки и виланы. Также мы можем организовывать сетевой трафик между разными стеками, имитируя различные конфигурации и тестовые случаи.
Еще одна проблема состояла в выработке механизма подготовки шаблонов для развертывания сред исполнения. Если вы не знаете, какими шагами был подготовлен базовый образ виртуальной машины, то по большому счету вы не сможете сделать никаких полезных выводов из результатов тестирования.
Решение, которое было применено, основывается на проекте Packer. Вокруг него написана обвязка, которая позволяет полностью автоматизировать подготовку образов для VirtualBox и Qemu, основываясь на официально опубликованных ISO-образах дистрибутива, и затем размещать готовые образы на серверах PVE или заливать на VagrantCloud.
Фактически этот метод эмулирует действия пользователя, если бы он сам скачал установочный образ и прошел процедуру инсталляции вручную. Что, в свою очередь, позволяет нам получать образы, максимально приближенные к средам пользователей.
Более того, подобный подход позволяет автоматически запускать примитивные тесты против подготовленных образов, чтобы убедиться, что базовый функционал работоспособен: с образа можно загрузиться, сервер ssh стартует и пускает с нужными ключами/паролями.
На данный момент проект находится в ранней стадии разработки. Сейчас он выполняет большинство задач, которые мы от него ждали. В первую очередь нам нужно было убедиться, что выбранная связка технологий и инструментов работоспособна и самое главное решение можно адаптировать под изменяющиеся в процессе эксплуатации требования, не затрачивая значительных усилий.
Второй важной задачей было убедиться, что этим инструментом смогут пользоваться люди, не имеющие большого опыта с ансиблом, PVE, деплоями и прочими devops-подобными вещами. Как правило, человеку, пишущему код и исправляющему баги, нужна «кнопка», которая будет разворачивать тестовое окружение, и нужен набор понятных «ручек», которые будут менять параметры этого окружения.
Частично эта задача тоже решена. Но уже сейчас видно, что некоторые вещи можно сильно упростить и сделать понятнее. Приятным дополнением явилось то, что гибкость получившегося инструмента позволила нам применить его и для развертывания продакшн инфраструктуры с необходимыми нам сервисами bind, dhcp-сервера, tftp, nginx и т.д., вся конфигурация которых лежит под управлением git, любое изменение подвергается code-review, и заинтересованные лица в любой момент могут посмотреть, кто и когда внес те или иные изменения, и при необходимости откатить всю инфраструктуру на любое прошлое состояние.
Планы на будущее
Так как проект изначально планировался как часть инфраструктуры непрерывной интеграции, то в ближайшие планы входит расширение поддерживаемых провайдеров виртуализации и контейнеризации, доведение до рабочего состояния функционала развертывания нод на голое железо различных архитектур (bare bone provisioning), расширение списка поддерживаемых приложений и сервисов, добавление более сложных вариантов конфигураций уже поддерживаемых приложений.
Получить экспертные ответы на все интересующие вопросы или воспользоваться широким спектром услуг по серверному администрированию можно здесь. Обращайтесь.