Написано на основе https://habrahabr.ru/company/oleg-bunin/blog/320984/
Это скорее конспект доклада, с которым можно ознакомится по ссылке выше, но для автора была важна общая картина и понимание механизмов построения решения, нежели тонкости и особенности конкретной реализации. Статья является продолжением цикла публикаций на тему DevOps решений в различных проектах.
Итак, речь пойдет о деплое кода от момента, когда разработчики больше не касаются подготовленного решения и до момента, когда это решение появляется в продуктивной среде. Кажется, что между этими событиями должно быть совсем немного времени, однако откроем занавес и увидим, что за этим стоит.
Система использует Puppet потому что это корпоративный стандарт. Конечно же, система конфигураций бесполезна без системы контроля версий. В описываемом случае используется Git. У каждого пользователя имеется свое окружение, именуемое по фамилии сотрудника. Это окружение используется для любых вариантов разработки (манифесты, модули, фитчи, альтернативные подходы) . Естественно, все, что прошло успешное тестирование будет синхронизировано с продуктивным окружением. Но пока об этом говорить рано.
Сервера управляются с помощью Puppet. Все. Без исключения. Для того, чтобы справится с большим количеством серверов используется Hiera – библиотека ruby, которая помогает лучше организовать данные в Puppet. Hiera (от hierarchy) оперирует иерархией, которая в описываемом случае следующая:
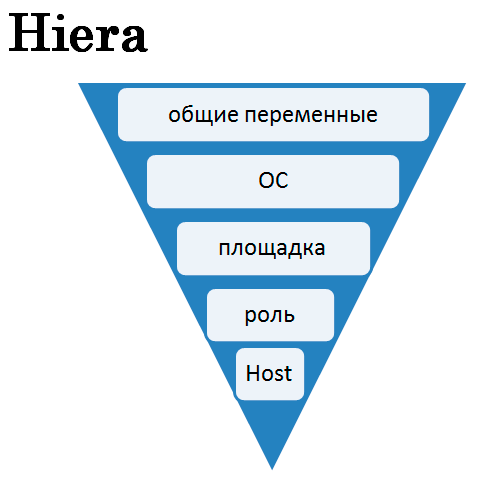
Площадка и ОС – служебные уровни. Используются для локализации трафиков внутри датацентров, и определения набора софта с учетом операционной системы (CentOS6, Centos7).
Ключевой уровень – это Роль. Собственно он определяет функционал сервера. Уровень общих переменных позволяет задать набор начальных значений, которые могут быть перезаписаны на более высоких уровнях, а уровень Host хранит настройки, максимально кастомизирующие сервер.
Написание манифестов подчиняется 3 правилам:
- Обнови версию.
- Не спали пароли
- Расскажи всем о том, что сделано.
Версия хранится в Hiera, для того, чтобы иметь возможность обеспечить возможность ее изменения в любое время в любом месте (на любом сервере).
Пароли хранятся в отдельном файле вне репозитария. А в репозитарии лежит только симлинк на этот файл. Стоит ли говорить, что этот файл имеет собственные механизмы контроля версий и резервного копирования?
Таким образом, отделу разработки доступны все модули и манифесты разрабатываемые нашей командой devOps, по сути, без доступа к паролям. Это обеспечивает возможность обмена опытом между командами и быструю корректировку решения при необходимости.
Рассказать всем – это правило хорошего тона. В компании есть система мониторинга, которая фиксирует факт появления новой роли на сервере. Причем не просто роли, а роли с достаточно конкретными пояснениями, которые отображаются в описании хоста в системе мониторинга. Это помогает очень быстро искать нужные instans’ы в инфраструктуре.
Непосредственно о деплое.
Организационно всю ответственность за развертывание в production несет админ, который выкатывает код. Не важно, насколько код рабочий. Если что-то сломалось – чинить это админу и все вопросы в первую очередь к нему. Автоматизация в этом случае неуместна. Поэтому разработан скрипт на Bash, основной задачей которого является брать код из ветки master и класть его в продуктивную среду. Опционально можно задать время, например, забрать код, актуальный на 9 утра. Дополнительная функция скрипта – логирование операции.
На случай если что-то пошло не так, не смотря на все проверки и тестирования, существует механизм отката к предыдущей версии. В описываемом случае это откат манифеста. Сотрудник компании говорит, что такой функционал потребовался один или два раза за 3 года, но, по его мнению, такой «резервный безотказный план» обязательно должен быть, несмотря на 100% уверенность в качестве выкладываемого кода.
На данном этапе стоит отойти на несколько шагов и посмотреть на общий порядок действий: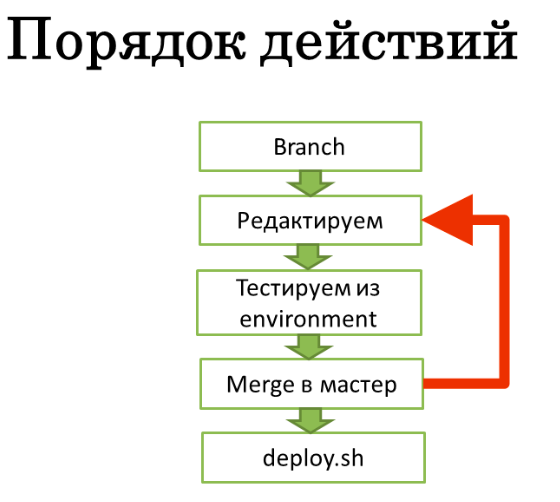
Так выглядит полный цикл: создается ветка от master, которая редактируется, тестируется и периодически ребейзится с master. Перед выкладыванием в продуктивную среду редактируемая ветка мерджится с master и запускается deploy.sh. Если merge неудачный – возврат к редактированию и повторение цикла.
Как знать, что ничего не сломалось? Для этого разработано специальное веб-приложение из которого производится накатка на сервера. Обновление накатывается на группу серверов, причем обычно на ограниченное количество серверов в группе. Помимо этого система отображает все сервера с цветовыми пометками: зеленые – система актуальна, желтые – имеются неустановленные обновления, красная – манифесты сломаны, и каталог для этого узла не строится. Итак, допустим, что визуально – все в порядке, но так ли это на самом деле?
С рабочего приложения собираются метрики. Хранит и отображает эти метрики open source решение Graphite. В описываемом проекте собирается больше 1 млн метрик.
Связующим звеном между Puppet и Graphite является система мониторинга. Мониторятся стандартные метрики, которые собирают собственно все: количество памяти дисков и пр. Но основной вопрос – как мониторить приложение? В данном случае работает еще одно не техническое, а организационное решение. Разработчики пишут ВСЕ логи приложения в одном формате: время, уровень ошибки, ее описание. Соответственно система мониторинга читает лог, и в случае обнаружения проблем выдает тревожно е сообщение в системе мониторинга.
Это все черновой мониторинг для внутренних нужд проекта. Конечно же, особо важные вещи агрегируются и отправляются в Большой Мониторинг, куда смотрят админы, контролирующие работу большого количества проектов.
По мнению автора этой статьи в докладе описан отличный пример сотрудничества разработчиков и DevOps. Разработчики, как основные создатели проекта получают огромное количество информации о том, где и как работает проект, начиная от конфигурации серверов и заканчивая статистикой логов и параметров работы приложения. При этом программист не затрачивает усилия на настройку систем, которые предоставляют эту информацию. DevOps в свою очередь получает качественный код, максимально адаптированный для работы в продуктивной среде, что снижает количество проблем и повышает качество конечного продукта.
Наша команда может организовать все технические средства для такой или подобной работы, обращайтесь office@itfb.com.ua