Uptime проекта на 100% многим представляется как миф. Современный рынок предлагает множество решений, обещающих предоставить возможности максимальной доступности либо предлагающие ее увеличить. Но не всегда они эффективно работают на практике, а в отдельных случаях могут снизить процент доступности. Какие же ошибки и проблемы приводят к подобной ситуации?
6 проблем снижения uptime
Для обеспечения 100-процентной доступности проекта важно уметь соотносить затраты со стоимостью даунтайма. Почему? Ответ прост: даже несколько минут недоступности могут привести к финансовым убыткам. Чтобы не наступать на чужие грабли, следует знать, какие ошибки допускаются на практике другими. Возможно рассмотренные выходы из создавшихся проблем, помогут вам избежать ошибочных шагов.
1. Весь проект локализован в одном месте (облачный хостинг, дата центр)
Бытует ошибочное мнение, что облачный хостинг не имеет привязки к железу, то есть инфраструктура в облаке просто не может упасть. Но реальность жестока, случаются и аварийные падения cloud (вспомните cloud4y или cloudmouse!). В результате – даунтайм на несколько часов.
Подобная ситуация и с «земными» дата центрами: все серверы пользователь резервирует в одном месте. Как только случится авария на одном из них, недоступность может заразить не только несколько стоек, но и весь центр.
Решение: попробовать наладить AWS-схему. Согласно ей, используется несколько availability zones, чем и достигается 100-процентный uptime.
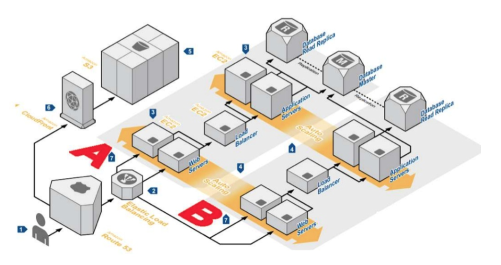
2.Нет адекватного дублирования на площадке-резерве
Исходя из предыдущей ситуации, вы принимаете решение создать площадку-резерв, так как она даст возможность получить максимум uptime. Но переход на нее требует своих условий: адекватность данных продакшн-площадки. Синхронизации возможных изменений:
- в конфигурации «кластер-данные в кластере» (для сложной площадки);
- в файловой структуре (+ отслеживание отставания);
- в конфигурации серверов;
- при добавлении основных сервисов/проектов (+ отладка процессов контроля);
- при подключении вторичных сервисов.
- Для наибольшей эффективности не забываем о постоянном мониторинге всего!
3.Не налажена регулярность переключений на площадку-резерв, не выполнено тестирование таких переходов
При самой тщательной организации мониторинга нет гарантии, что подготовленная в качестве резерва площадка будет в необходимый момент готова к переключению. Поэтому все нужно проверять в реальных условиях. Пример Stack Overflow показывает, что может потребоваться не один тестовый переход на резервные точки, а намного больше.
Решение: в план по увеличению доступности проекта заранее необходимо внести тестовые проверки/переходы на площадку-резерв. При этом следует учитывать, что каждая из них не исключает аварийной ситуации.
4.Площадка-резерв локализована в одном месте (будь это канал либо регион облака)
Одна хостинг-организация может локализовать свой продукт и площадку для резервов к нему в одном месте. Но последствия такой ошибки печальны: при аварийной ситуации отключится все!
Выход: создать конфигурацию с площадкой-резервом на базе своего хостинга (здесь будут размещены штатные средства, помогающие в переключении на место-резерв) + со вторичной на базе другого хостинга.
5.Одни и те же данные размещены и на площадке-резерве, и на основной
Решение предыдущей проблемы также не дает гарантии, что подготовленные резервы будут готовы в ответственный момент сработать на максимальном уровне и взять на себя нагрузку продакшн. Ситуация объясняется самой сутью процесса резервирования. На площадке-резерве будет сформирована точно такая же фатальная нагрузка, что и на площадке-продакшн. В итоге полный даунтайм проекта обеспечен.
Выход: продумать механизм отката продукта до предыдущей версии на еще одной площадке. Здесь в тему будет упомянуто резервное копирование – отложенная репликация на некоторый период времени (например, на 1 час). Такое решение поможет в момент аварии выполнить переход на ту БД, где ситуация еще не претерпела никаких изменений.
6.Проект зависим от внешних сервисов
Часто в проектах задействуют внешние службы – СМС для аутентификации на сайте, службы доставки от интернет-магазинов, сторонние кошельки для оплаты услуг и т.д. В случае недоступности такого сервиса извне о качественном обслуживании клиентов можно забыть.
Решение: дублирование критических внешних сервисов с последующим отслеживанием их доступности. И, конечно же, включение в план их переключений в случае аварийной ситуации.
Надеемся, что наши рекомендации и советы помогут вам обеспечить 100% uptime проекта. Если желаете добиться максимально доступности вашего проекта, обращайтесь.