Во FreeBSD еще в 2000-м году появился механизм jail, прозванный «chroot на стероидах». Он позволил отделить процессы основной системы от процессов внутри chroot/jail, ограничить доступ к сети и переменным ядра, назначить каждому виртуальному окружению собственный hostname, а начиная с FreeBSD 9.0 — ограничить использование ресурсов.nnРазработчики Linux реализовали концепцию «пространств имен» (namespaces). Это уже комплексный более универсальный механизм, разрешающий выполнять над ресурсами ядра (список процессов, разделяемая память, сетевой стек) примерно ту же операцию, что chroot выполняет над файловой иерархией, то есть отрезать выбранное приложение от основной системы. Существует множество разных типов пространств имен:n
- PID — пространство имен процессов, ограничивает область видимости только процессами, которые были порождены самим приложением, и закрывает доступ ко всем остальным процессам системы;
- Mount — позволяет монтировать файловые системы так, чтобы они были видны только самому приложению и его потомкам;
- IPC — отрезает процессы, использующие разделяемую память, семафоры и очереди сообщений, от процессов хост-системы;
- Network — создает отдельный сетевой стек для приложения и его потомков, с собственными IP-адресами, правилами брандмауэра, таблицами маршрутизации, правилами QoS и так далее;
- UTS — позволяет привязать к приложению и потомкам собственное доменное имя;
- User — создает собственную таблицу пользователей и групп. Красота пространств имен в том, что их очень просто применить. Достаточно запустить приложение под управлением команды unshare, передав ей несколько флагов. Попробуй для примера выполнить следующую команду:
$ sudo unshare -p --fork --mount-proc /usr/bin/ps -aux
Несмотря на то что мы прямо попросили ps показать все системные процессы (флаги -aux), в списке процессов оказывается только сам ps. Такое происходит потому, что мы запустили ps в собственном пространстве имен процессов (флаг -p и флаги —fork и —mount-proc, чтобы смонтировать /proc по новой уже после применения пространства имен). Можешь заменить /usr/bin/ps на /usr/bin/top, чтобы убедиться, что top тоже не может «заглянуть» за пределы пространства имен.nn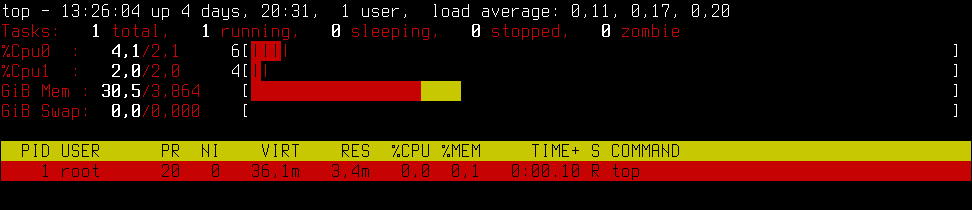 nnКоманда unshare позволяет запускать приложение и в любых других пространствах имен, поэтому, объединив ее с командой chroot, мы можем создать по-настоящему изолированную песочницу:n
nnКоманда unshare позволяет запускать приложение и в любых других пространствах имен, поэтому, объединив ее с командой chroot, мы можем создать по-настоящему изолированную песочницу:n
$ sudo unshare -piumU --fork --mount-proc chroot ~/sandbox /bin/ls -l /
Эта команда создаст все перечисленные выше пространства имен (кроме сетевого) и запустит /bin/ls внутри них. Это уже почти настоящее виртуальное окружение с собственным точками монтирования, юзерами, списком процессов. Единственное, чего не хватает, — это выделенный сетевой стек (сетевое пространство имен). Его мы создадим с помощью другой команды — ip. Но для начала нам нужен виртуальный сетевой мост, который будет служить выходом виртуального окружения в сеть.nnСоздаем сетевой мост и подключаем его к физическому сетевому интерфейсу eth0 (у тебя его имя, скорее всего, будет другим, запусти ifconfig, чтобы узнать точно):n
$ sudo brctl addbr br0n$ sudo brctl addif br0 eth0n$ sudo dhcpcd br0
Далее создаем новое сетевое пространство имен (назовем его sandbox), а также пару сцепленных друг с другом виртуальных сетевых интерфейсов (veth), один из которых (eth1) пробросим в это пространство имен:n
$ sudo ip netns add sandboxn$ sudo link add veth1 type veth peer name eth1n$ sudo link set eth1 netns sandbox
Подключаем виртуальный сетевой интерфейс к мосту и запускаем dhcpcd для получения IP-адреса:n
$ sudo brctl addif br0 veth1n$ sudo ip link set veth1 upn$ sudo ip netns exec dhcpcd eth1
В качестве последнего штриха добавляем в виртуальное окружение адрес DNS-сервера (это будет гугловский 8.8.8.8):n
$ sudo mkdir ~/sandbox/etcn$ sudo echo 'nameserver 8.8.8.8' > ~/sandbox/etc/resolv.conf
Осталось только запустить наше виртуальное окружение в полученном пространстве имен:n
$ sudo ip netns exec unshare -piumU --fork --mount-proc chroot ~/sandbox /bin/ls -l /
Воздвигаем стены
Для примера с /bin/ls это неважно, но настоящее виртуальное окружение также должно ограничивать доступные приложению ресурсы, будь то процессор, память или пропускная способность дисковой подсистемы. Для этих целей в ядре Linux есть механизм cgroups (control groups), позволяющий объединить процессы в группы и привязать к ним так называемые контроллеры,которые будут ограничивать те или иные ресурсы. Всего существует около десятка различных контроллеров, наиболее полезные из них:n
- blkio — устанавливает лимиты на скорость ввода-вывода;
- cpu — позволяет ограничить использование процессора;
- cpuset — привязывает группу процессов к определенному процессорному ядру;
- devices — открывает/закрывает доступ к определенным устройствам;
- freezer — позволяет замораживать процессы в группе;
- memory — устанавливает лимиты на использование оперативной памяти.
Мы для простоты будем использовать только два контроллера: cpu и memory. Для начала создадим группу контроллеров:n
$ sudo cgcreate -g cpu,memory:/sandbox
Далее установим лимиты. С памятью все просто, указываем прямым текстом 128 Мбайт:n
$ sudo cgset -r memory.limit_in_bytes=128M sandbox
С процессором дела обстоят несколько сложнее. Здесь необходимо указывать период процессорного времени в миллисекундах и квоту, выделенную группе процессов на этот период. Например, если мы хотим, чтобы наша группа процессов (приложение) получала доступ к процессорным ресурсам на одну десяnтую секунды каждую секунду, то нужно выполнить следующую команду:n
$ sudo cgset -r cpu.cfs_period_us=1000000 -r cpu.cfs_quota_us=100000 sandbox
Обрати внимание, что данная настройка относится только к одному процессору, то есть на двухъядерной системе приложение будет получать процессор в два раза реже, а на четырехъядерной — в четыре раза реже. Еще один момент: данная настройка вовсе не значит, что приложение получит 10% процессорной мощности, она всего лишь гарантирует, что приложение не будет получать доступ к процессору реже, чем мы указали. Если система простаивает, то планировщик может выделить приложению гораздо больше времени для работы.nnНу и в завершение нам необходимо запустить наше приложение под управлением cgroups:n
$ sudo cgexec -g cpu,memory:/sandbox ip netns exec unshare -piumUn--fork --mount-proc chroot ~/sandbox /bin/ls -l /
Вуаля, мы получили полноценное виртуальное окружение, полностью отрезанное от основной системы, с ограничением ресурсов и выходом в сеть через виртуальный шлюз.n
Собираем все всместе
Теперь, когда мы знаем, как создать песочницу, мы можем написать скрипт, который делает это все за нас. Вот он: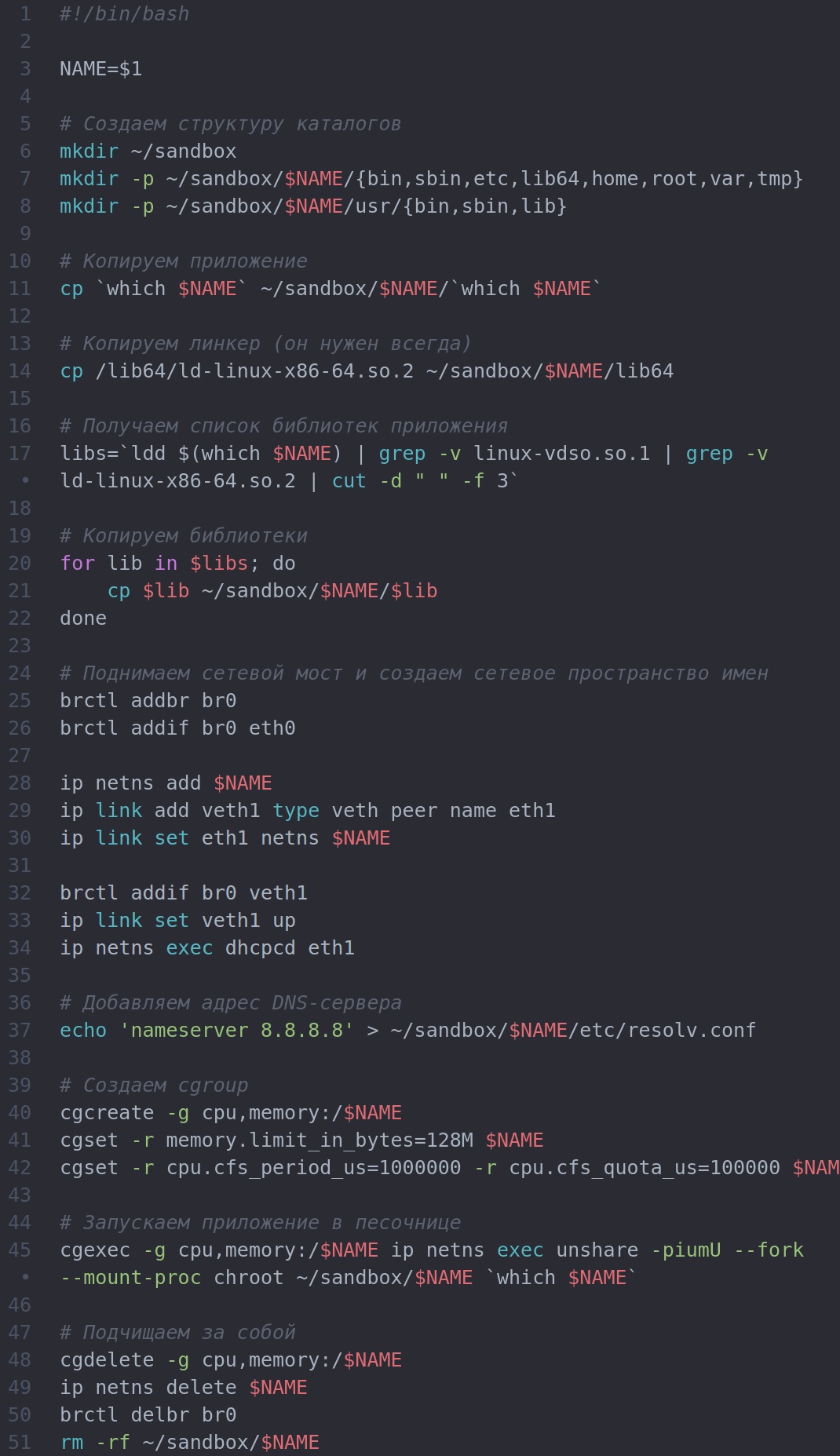 nnПользоваться скриптом очень просто. Достаточно просто указать имя приложения:n
nnПользоваться скриптом очень просто. Достаточно просто указать имя приложения:n
$ sudo sandbox.sh ps
Далее скрипт создаст выделенную песочницу в каталоге ~/sandbox, скопирует в него приложение и его зависимости, настроит сетевой мост и cgroups и запустит приложение, после чего удалит песочницу и сбросит настройки. Для простоты аргументы игнорируются. Также не пытайся с его помощью запустить сложный, а тем более графический софт, зависящий от файлов настроек и других данных, которые этот скрипт не умеет копировать в песочницу.n
Вывод
Ядро Linux имеет все необходимые средства для создания изолированных окружений исполнения. Те же самые технологии можно использовать для запуска не только отдельно взятых приложений, но и целых дистрибутивов. Для этого достаточно скопировать в каталог песочницы все файлы дистрибутива, смонтировать каталоги /dev и /proc, а затем запустить /bin/init.nnНу а популярность Docker обусловлена всего лишь тем, что он позволил делать все это с помощью одной простой команды, без необходимости самому копировать зависимые библиотеки и возиться с настройками.nnИсточник: журнал Хакер №211n
itfb предоставляет услуги по установке и настройке Docker, обращайтесь office@itfb.com.ua