В прошлой статье мы говорили о таком инструменте поиска (точнее наборе инструментов), как ELK. Как выяснилось, он отлично подходит как для поиска, так и для аналитики больших объемов неструктурированных данных. В качестве альтернативного варианта рассматривался продукт SolrCloud.nnЭто продукт, который базируется (также как и ELK) на Apache Lucene и является её логическим продолжением, как с точки зрения логики, так и с точки зрения разработки.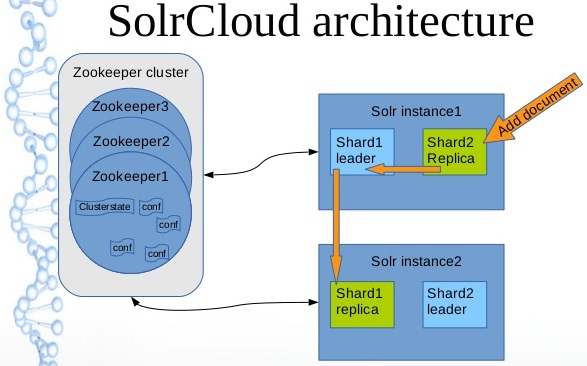 nnДавайте вначале поговорим о «Cloud» – второй части в названии продукта. Она добавляет продукту возможности по горизонтальному масштабированию, такие как обеспечение избыточности и отказоустойчивости.nnСам же продукт Solr скорее сравним с частью ELK, а именно — Elasticsearch. Он также осуществляет поиск по полученным неструктурированным данным. Для взаимодействия с собой имеет собственный CLI интерфейс и API для различных языков веб разработки. Для индексации данных Solr создает их схему, автоматически определяя поля и их типы. Однако для обеспечения правильного индексирования рекомендуется задавать схему вручную. Для вывода информации в виде веб-страницы требуется разработка. В особенностях использования поиска следует отметить необходимость дополнительной настройки для корректного использования русского языка. Solr — это нечто среднее, уже не простой поисковый движок, но еще не полноценная NoSQL Database. Он хранит свои индексы в оперативной памяти, однако не поддерживает динамическое обновление новых индексов для существующих полей.nnВ эксплуатации необходимо заметить еще один важный аспект: наличие документации. Здесь выигрывает Solr в сравнении с Elasticsearch, поскольку его инструкции более удобны для чтения и понимания.nnТаким образом, Solr применим в первую очередь при организации полнотекстового поиска на разных ресурсах, таких как форумы, новостные ленты и т.п., поиске по текстовым данным больших объемов, а также поиске с использованием геолокации и заданного региона. Иногда механизм Solr (и ему подобные) используют для повышения быстродействия при поиске информации по ресурсу.
nnДавайте вначале поговорим о «Cloud» – второй части в названии продукта. Она добавляет продукту возможности по горизонтальному масштабированию, такие как обеспечение избыточности и отказоустойчивости.nnСам же продукт Solr скорее сравним с частью ELK, а именно — Elasticsearch. Он также осуществляет поиск по полученным неструктурированным данным. Для взаимодействия с собой имеет собственный CLI интерфейс и API для различных языков веб разработки. Для индексации данных Solr создает их схему, автоматически определяя поля и их типы. Однако для обеспечения правильного индексирования рекомендуется задавать схему вручную. Для вывода информации в виде веб-страницы требуется разработка. В особенностях использования поиска следует отметить необходимость дополнительной настройки для корректного использования русского языка. Solr — это нечто среднее, уже не простой поисковый движок, но еще не полноценная NoSQL Database. Он хранит свои индексы в оперативной памяти, однако не поддерживает динамическое обновление новых индексов для существующих полей.nnВ эксплуатации необходимо заметить еще один важный аспект: наличие документации. Здесь выигрывает Solr в сравнении с Elasticsearch, поскольку его инструкции более удобны для чтения и понимания.nnТаким образом, Solr применим в первую очередь при организации полнотекстового поиска на разных ресурсах, таких как форумы, новостные ленты и т.п., поиске по текстовым данным больших объемов, а также поиске с использованием геолокации и заданного региона. Иногда механизм Solr (и ему подобные) используют для повышения быстродействия при поиске информации по ресурсу.